
Тема 5. Природні алгоритми
Всі алгоритми, що натхненні живою природою відносяться до класу евристичних алгоритмів (Heuristic Algorithms), тобто алгоритмів, для яких збіжність до глобального вирішення не є доведеною, але експериментально встановлено, що в більшості випадків вони дають досить гарне рішення.
Дослідження, що відбуваються у цьому напрямку можна умовно поділити на
Природні моделі. Це системи, які відтворюють біологічні популяції або системи і не є корисними в прикладному сенсі. Природні моделі відтворюють розвиток біологічних системи, мають складну поведінку і зазвичай не використовуються для вирішення технічних завдань. До цих систем відносять так зване «штучне життя».
Природні алгоритми. Це системи, які використовують та моделюють біологічні принципи діяльності та розвитку популяції. Вони успішно використовуються для завдань евристичного пошуку, оптимізації і можуть легко бути описані математичною мовою. Дані інтелектуальні алгоритми часто називають популяційними або поведінковими. Популярними для вирішення різного типу завдань є:
Еволюційні алгоритми (генетичний алгоритм та еволюційні стратегії).
Алгоритми колективної поведінки (мурашиний алгоритм).
Алгоритми ройового інтелекту (алгоритм рою частинок, бджолиний алгоритм тощо)
Алгоритми колективної діяльності людей (наприклад, алгоритм еволюції розуму).
Інші алгоритми, що запозичені з живої та неживої природи.
5.1. Постановка задачі оптимізації
У найпростішому випадку задача оптимізації полягає у знаходженні екстремуму (мінімуму або максимуму) цільової функції шляхом систематичного перебору вхідних значень з дозволеного набору та обчислення її значення.
Y= f(x1, x2, ..., xn)
Y називається цільовою функцією, що залежить від параметрів(x1, x2, ..., xn) і в залежності від задачі прагне до максимального чи мінімального значення.
Для більшої наочності можна навести приклад великого підприємства, що виробляє певні товари і пов’язане з багатьма іншими підприємствами (постачальники сировини чи комплектуючих, збут продукції, маркетинг, гуртовий продаж, партнери). Діяльність підприємства залежить від багатьох факторів (параметрів), які можуть змінюватися в широкому або обмеженому діапазоні.
Нехай, ставиться завдання збільшити дохід компанії і знайти ті чинники і їх значення, що цьому сприятимуть. У цьому випадку цільовою функцією буде «Дохід компанії», що прямо чи опосередковано залежить від багатьох параметрів, таких як число працівників компанії, обсяг виробництва, витрати на рекламу, ціни на кінцеві продукти тощо. Ці параметри пов'язані між собою - наприклад, при зменшенні числа працівників швидше за все впаде й обсяг виробництва.
В даній постановці завданням є знайти таку комбінацію значень вхідних параметрів, щоб цільова функція була як можна максимальною.
Деякі задачі оптимізації (з невеликою кількістю параметрів та діапазону їх змін) легко розв’язати, але є і такі, точне рішення яких знайти практично неможливо (знайти максимальне значення цільової функції, що залежить від значної кількості параметрів з широким діапазоном значень).
Відомо два основні шляхи вирішення таких задач - переборний та градієнтний.
Переборний метод. Для пошуку оптимального рішення (максимум цільової функції) потрібно послідовно обчислити значення функції у всіх точках. Метод є простим, але потребує великої кількості обчислень і часу.
Градієнтний спуск. Обираються випадкові значення параметрів, які поступово змінюються, досягаючи найбільшої швидкості зросту цільової функції. Алгоритм може зупинитись, досягнувши локального оптимуму (максимуму чи мінімуму). Градієнтні методи швидкі, але не гарантують оптимального рішення (оскільки цільова функція має як глобальний оптимум так і декілька локальних оптимумів).
Ефективним способом вирішення задач оптимізації є природні алгоритми, що представляють комбінацію переборного та градієнтного методів. Тобто, якщо на деякій множині задано складну функцію від багатьох змінних, тоді природні алгоритми є програмами, які за визначений час знаходять точку, де значення функції знаходиться достатньо близько до максимально можливого значення, це буде одним з кращих рішень.
Для кращого розуміння природніх алгоритмів потрібно роз'яснити поняття поверхні станів цільової функції. Кожному значенню параметрів кількістю N відповідає один вимір в багатовимірному просторі. N+1-ий вимір відповідає значенню цільової функції. Для різноманітних сполучень значень параметрів відповідне значення цільової функції можна зобразити точкою в N+1-вимірному просторі. Всі ці точки утворюють деяку поверхню - поверхню станів. Метою використання природніх алгоритмів є знаходження на багатовимірній поверхні найвищої або найнижчої точки, що відповідатиме значенню цільової функції.
Поверхня станів має складну будову і досить неприємні властивості, зокрема, наявність локальних мінімумів (точки, найнижчі в своєму певному околі, але вищі від глобального мінімуму), пласкі ділянки, сідлові точки і довгі вузькі яри. Аналітичними засобами неможливо визначити розташування глобального мінімуму на поверхні станів, тому робота природніх алгоритмів полягає в дослідженні цієї поверхні.
Відштовхуючись від початкової конфігурації параметрів (від випадково обраної точки/точок на поверхні), алгоритми поступово відшукують глобальний оптимум (максимум чи мінімум) цільової функції. Обчислюється вектор напрямку та розмір кроків просування по поверхні з заданої точки (рис.5.1).
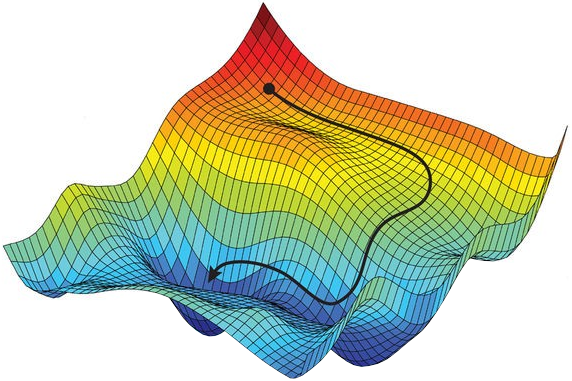
Рис.5.1. Наочний приклад пошуку глобального оптимуму
Алгоритми діють ітеративне, на кожній ітерації перевизначається знайдене значення цільової функції, що порівнюється з попередніми значеннями і обчислюється похибка. Значення похибки використовують для корекції певних коефіцієнтів (напрямок і довжина кроків просування по поверхні), і дії повторюються. Робота алгоритму припиняється або коли пройдена визначена кількість ітерацій, або коли похибка досягає визначеного рівня малості, або коли похибка перестає зменшуватись. Користувач переважно сам вибирає потрібний критерій припинення обчислень.
Зрештою алгоритм зупиняється в точці оптимуму, що може виявитись лише локальним оптимумом (в ідеальному випадку - глобальним).
Складність в алгоритмах полягає у виборі довжини кроків. При великій довжині кроку збіжність буде швидшою, але є небезпека перестрибнути рішення, або просуватися в невірному напрямку. При маленьких кроках, правильний напрямок буде виявлено, але зростає кількість ітерацій. На практиці розмір кроків береться пропорційним до крутизні схилу з деякою константою - швидкістю навчання. Правильний вибір швидкості навчання залежить від конкретної задачі і здійснюється дослідним шляхом. Ця константа може також залежати від часу, зменшуючись в міру просування алгоритму.
5.1.1. Основні терміни популяційних алгоритмів
В природніх алгоритмах для назви членів популяції використовується термін агент (agent). В різних популяційних алгоритмах агентів позначають термінами – особини, індивіди тощо.
Загальна схема популяційних алгоритмів містить наступні етапи:
Ініціалізація популяції. В області пошуку в різний спосіб розміщується певна кількість початкових наближень до шуканого рішення задачі - ініціалізація популяції агентів.
Міграція агентів популяції. За допомогою певного набору операторів переміщення, специфічних для кожного з популяційних алгоритмів, агенти в області пошуку переміщаються таким чином, щоб в кінцевому рахунку наблизитися до шуканого екстремуму цільової функції.
Завершення пошуку. Перевіряється виконання умов закінчення ітерацій, і якщо їх виконано, обчислення завершуються, приймаючи краще із знайдених станів агентів популяції за наближене рішення задачі. Якщо зазначені умови не виконано, етап 2 повторюється.
При ініціалізації популяції можуть бути використані детерміновані і випадкові алгоритми. Істотно скоротити час вирішення завдання може формування початкової популяції, агенти якої знаходяться поблизу глобального оптимуму цільової функції. Однак, зазвичай, апріорна інформація про місцезнаходження цього екстремуму є відсутньою, тому, агентів початкової популяції розподіляють рівномірно по всій області пошуку.
Як умову завершення пошуку використовують, як правило, досягнення заданого числа ітерацій (поколінь). Часто використовують також умову стагнації (stagnation) алгоритму, коли краще досягнуте значення цільової функції не змінюється протягом заданого числа ітерацій. Можуть бути використані й інші умови, наприклад, умова вичерпання часу, що відведено на вирішення завдання.
Більшість популяційних алгоритмів мають яскраво виражену модульну структуру, що дозволяє легко отримати велику кількість варіантів кожного з алгоритмів шляхом комбінування правил ініціалізації популяції, операторів переміщення і умов завершення пошуку.
Агентам популяції притаманні основні властивості.
Автономність - агенти пересуваються в просторі пошуку, зазвичай, незалежно один від одного.
Стохастичність - процес пересування агентів містить випадкову компоненту.
Обмеженість уявлення - кожен з агентів популяції має інформацію лише про частину області пошуку, в якій він просувається і, можливо, про оточення деяких інших агентів.
Децентралізація - відсутність агентів, які керують процесом пошуку в цілому.
Комунікабельність - агенти в різний спосіб можуть обмінюватися між собою інформацією про топологію (ландшафт) поверхні станів цільової функції, що виявлено в процесі дослідження своєї частини області пошуку.
Навіть, якщо стратегія поведінки кожного з агентів популяції досить проста, зазначені властивості агентів забезпечують формування колективного інтелекту, який проявляється в самоорганізації і складній поведінці популяції в цілому.
Еволюційні алгоритми
До них відносяться:
Генетичні алгоритми.
Еволюційні стратегії.
Генетичне програмування.
Еволюційне програмування.
Еволюційні алгоритми – це загальна назва алгоритмів пошуку, оптимізації або навчання, що засновані на принципах природного еволюційного процесу. Вони призначені для ітераційного пошуку бажаних рішень. На відміну від точних математичних методів еволюційні методи дозволяють за прийнятний час знаходити рішення, наближені до оптимальних та характеризуються меншою залежністю від особливостей завдання.
5.2. Генетичний алгоритм
Генетичний алгоритм - це евристичний алгоритм пошуку, який застосовується для вирішення завдань оптимізації, що нагадує біологічну еволюцію.
Еволюція - це процес постійної оптимізації біологічних видів. Еволюційна теорія стверджує, що життя на планеті виникло спочатку лише в найпростіших формах - у вигляді одноклітинних організмів. Ці форми поступово ускладнювалися, пристосовуючись до навколишнього середовища, породжуючи нові види, і через багато мільйонів років з'явилися перші тварини і люди. Кожен біологічний вид з часом вдосконалює свої якості, щоб ефективно справлятися з важливими задачами виживання, самозахисту, розмноження. Таким чином виникло захисне забарвлення в багатьох риб і комах, панцир у черепахи, отрута в скорпіона тощо.
За допомогою еволюції природа постійно оптимізує живі організми, знаходячи часом неординарні рішення, ґрунтуючись лише на двох біологічних механізмах - природного відбору і генетичного спадкування.
Природний відбір гарантує, що найбільш пристосовані особини надають більшу кількість нащадків, а завдяки генетичному спадкуванню частина нащадків не лише збереже високу пристосованість батьків, але буде мати і деякі нові властивості. Якщо нові властивості виявляються корисними, то з великою імовірністю вони перейдуть до наступного покоління. Таким чином, відбувається нагромадження корисних якостей і поступове підвищення пристосованості біологічного виду в цілому. Знаючи, як вирішується задача оптимізації видів у природі, можна застосувати схожий метод для вирішення реальних завдань.
Для ясного розуміння спадковості, потрібно дещо поглибитися в побудову природної клітини - у світ генів і хромосом. Майже в кожній клітині будь-якої особини є набір хромосом, що містять інформацію про цю особину. Основна частина хромосоми - нитка ДНК, яка визначає, які хімічні реакції будуть відбуватися в даній клітині, як вона буде розвиватися і які функції виконувати (рис.5.2).
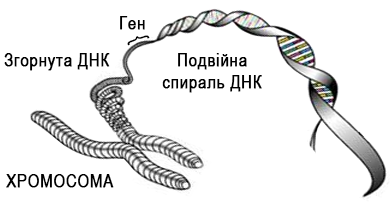
Рис.5.2. Спрощене представлення складу хромосоми
В будь якому організмі присутні два види клітин: статеві (такі, як сперматозоїд і яйцеклітина) і соматичні.
Соматичні клітини містять 23 пари (46 хромосом): 22 пари нестатевих хромосом і одна пара статевих хромосом (Х і Y хромосоми). В кожній парі одна з хромосом отримана від батька, а друга - від матері (рис.5.3).
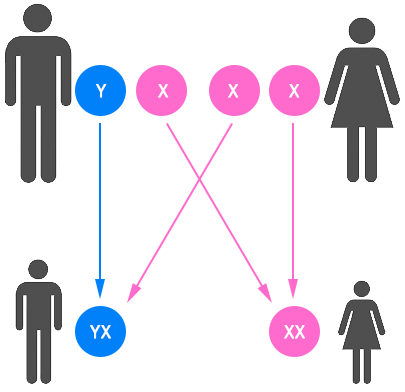
Рис. 5.3. Процес наслідування хромосом
В статевих клітинах хромосом лише 23, і вони непарні. При заплідненні відбувається об’єднання чоловічої і жіночої статевих клітин і утворюється клітина зародка, що містить саме 46 хромосом. Які властивості нащадок одержить від батька, а які - від матері? Це залежить від того, які саме статеві клітини брали участь у заплідненні.
При статевому розмноженні людини (мейоз) зливаються дві окремі статеві клітини, які продукують соматичну клітину. Чоловічі сперматозоїди містять один з двох типів статевих хромосом X або Y. Жіночі яйцеклітини містять тільки Х-хромосому. В цьому випадку клітина сперми визначає стать індивідуума. Якщо сперматозоїдна клітина, яка містить Х-хромосому, запліднює яйцеклітину, результуючою соматичною клітиною XX - жіноча стать. Якщо клітина сперми містить Y-хромосому, тоді результуючою буде XY - чоловіча стать.
Ген - це частина хромосоми (ланка ДНК), який відповідає за певну властивість особини, наприклад за колір очей, тип волосся, колір шкіри тощо. Вся сукупність генетичних ознак людини кодується за допомогою приблизно 60 тис. генів.
Парні хромосоми відповідають за однакові ознаки - наприклад, батьківська хромосома може містити ген чорного кольору око, а парна їй материнська - ген голубого кольору. Існують визначені закони, що керують участю тих чи інших генів у розвитку особини. Зокрема, у даному прикладі нащадок буде чорнооким, оскільки ген блакитних очей є "слабшим" і подавляється геном будь-якого іншого кольору.
Процес вироблення соматичних клітин в організмі піддається змінам, завдяки яким нащадки відрізняються від своїх батьків. Зокрема, відбувається наступне: парні хромосоми соматичної клітини зближаються впритул, потім їхні нитки ДНК розриваються в кількох випадкових місцях і хромосоми обмінюються своїми частинами (рис.5.4).
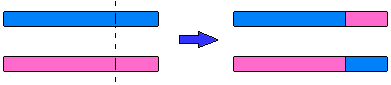
Рис.5.4. Спрощене представлення процесу схрещування
Цей процес забезпечує появу нових варіантів хромосом і зветься "кросовер" (crossover, crossingover або схрещування). Кожна з нових хромосом з'являється потім всередині однієї з статевих клітин, і її генетична інформація може реалізуватись в нащадках даної особини.
Важливим фактор, що впливає на спадковість є мутації, які виражаються в зміні деяких ділянок ДНК. Мутації є випадковими і можуть бути викликані різними зовнішніми факторами. Якщо мутація відбулася в статевій клітині, то змінений ген може передатися до нащадку і проявитися у вигляді нових властивостей. Саме мутації є причиною появи нових біологічних видів, а кросовер визначає вже змінність всередині виду.
Загальна ідея генетичного алгоритму
Генетичний алгоритм є методом багатовимірної оптимізації, тобто методом пошуку оптимуму багатовимірної функції. Потенційно цей метод можна використовувати для глобальної оптимізації, але з цим виникають складності. Суть методу полягає в моделюванні еволюційного процесу: є певна популяція (набір векторів), яка розмножується, на яку впливають мутації і проводиться природний відбір на підставі оптимізації цільової функції.
Отже, перш за все популяція повинна розмножуватися. Основний принцип розмноження - нащадок схожий на своїх батьків. Тобто потрібно задати механізм успадкування, що містить елемент випадковості. Швидкість розвитку таких систем дуже низька – генетична різноманітність зменшується, популяція вироджується. Тобто значення функції перестає мінімізуватися.
Для вирішення цієї проблеми використовується механізм мутації, який полягає в випадковій зміні випадкових особин. Цей механізм дозволяє ввести щось нове в генетичну різноманітність.
Наступний важливий механізм - селекція - відбір особин, які краще оптимізують функцію. Зазвичай, відбирають стільки особин, скільки було до розмноження, щоб в кожній епосі була постійна кількість особин в популяції. Також прийнято відбирати випадкових особин, які, можливо, погано оптимізують функцію, але зате вносять різноманітність в наступні покоління.
Цих трьох механізмів може забракнути, щоб мінімізувати функцію. Так популяція вироджується - рано чи пізно популяція може застрягнути в локальному оптимумі. Коли таке відбувається, проводять процес, званий струсом (в природі аналогії - глобальні катаклізми), коли знищується майже вся популяція, і вводяться нові (випадкові) особини.
Це опис класичного генетичного алгоритму, він простий в реалізації і є місце для фантазії і досліджень.
Практичний приклад генетичного алгоритму
Для того, щоб говорити про генетичне спадкування, потрібно наділити особини хромосомами. В генетичному алгоритмі хромосома - це числовий вектор набору параметрів, що сприяють вирішенню задачі. Які саме вектори варто розглядати в конкретній задачі, вирішує користувач. Кожна з позицій вектору хромосоми називається геном і відповідає за певний вхідний параметр.
Наприклад, в завданні знайти найкращі рішення для збільшення прибутків від діяльності компанії цільовою функцією буде «Дохід компанії», що прагне до максимуму і залежить від певних чинників
Дохід компанії = f («собівартість продукції», «витратні матеріали», «заробітна платня», «амортизаційні витрати», …)
В термінах генетичного алгоритму «Дохід компанії» є хромосомою. Чинники, що впливають на цільову функцію будуть розглядатися як гени («собівартість продукції», «витратні матеріали», «заробітна платня», «амортизаційні витрати»). Тоді хромосоми «Дохід компанії» можна представити як набір генів. Кожен ген, що відповідає за певний чинник може містити різні значення.
Хромосома 1 – 15, 200, 5000, 100
Хромосома n – 12, 260, 3800, 112
Зазвичай для спрощення обчислень в генетичних алгоритмах кожен ген представлено у двійковому коді
Хромосома 1 – 10001111000 00001001000 10001111100 11101111011
Хромосома n – 10101101100 01101001011 10110011100 11101001000
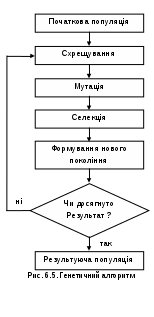
В загальному роботу генетичного алгоритму можна описати основними етапами (рис.4.5).
1. Генерація початкової популяції, що складається з особин, вибраних випадковим чином.
2. Для кожної особини алгоритм обчислює ймовірність Ps(i), яка дорівнює відношенню її пристосованості до сумарної пристосованості популяції:
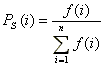
3. Відповідно до величини Ps(і) відбувається відбір найсильніших n особин для подальшої генетичної обробки. Члени популяції з високою пристосованістю будуть вибиратися з більшою імовірністю, ніж особини з низькою пристосованістю.
4. Після відбору, n обраних особин випадковим чином поділяються на n/2 пари, які будуть схрещуватися між собою.
5. Для кожної пари застосовується схрещування (кросовер). Кросовер - це операція, при якій із двох хромосом породжується кілька нових хромосом. Для одноточкового кросоверу випадковим образом вибирається точка розриву (ділянка між сусідніми ланками в рядку). Обидві батьківські структури розриваються на два сегменти в цій точці. Потім, відповідні сегменти різних батьків склеюються і виходять два генотипи нащадків.
Наприклад, припустимо, один батько складається з 10 нулів, а інший - з 10 одиниць. Нехай з 9 можливих точок розриву обрано точку 3. Нижче представлено батьківські особини та утворені їхні нащадки.
Батько 1 0000000000 000
0000000--> 111
0000000 1110000000 Нащадок 1
Батько 2 1111111111 111
1111111 --> 000
1111111 0001111111 Нащадок 2 Тема 5. Природні алгоритми
Всі алгоритми, що натхненні живою природою відносяться до класу евристичних алгоритмів (Heuristic Algorithms), тобто алгоритмів, для яких збіжність до глобального вирішення не є доведеною, але експериментально встановлено, що в більшості випадків вони дають досить гарне рішення.
Дослідження, що відбуваються у цьому напрямку можна умовно поділити на
Природні моделі. Це системи, які відтворюють біологічні популяції або системи і не є корисними в прикладному сенсі. Природні моделі відтворюють розвиток біологічних системи, мають складну поведінку і зазвичай не використовуються для вирішення технічних завдань. До цих систем відносять так зване «штучне життя».
Природні алгоритми. Це системи, які використовують та моделюють біологічні принципи діяльності та розвитку популяції. Вони успішно використовуються для завдань евристичного пошуку, оптимізації і можуть легко бути описані математичною мовою. Дані інтелектуальні алгоритми часто називають популяційними або поведінковими. Популярними для вирішення різного типу завдань є:
Еволюційні алгоритми (генетичний алгоритм та еволюційні стратегії).
Алгоритми колективної поведінки (мурашиний алгоритм).
Алгоритми ройового інтелекту (алгоритм рою частинок, бджолиний алгоритм тощо)
Алгоритми колективної діяльності людей (наприклад, алгоритм еволюції розуму).
Інші алгоритми, що запозичені з живої та неживої природи.
5.1. Постановка задачі оптимізації
У найпростішому випадку задача оптимізації полягає у знаходженні екстремуму (мінімуму або максимуму) цільової функції шляхом систематичного перебору вхідних значень з дозволеного набору та обчислення її значення.
Y= f(x1, x2, ..., xn)
Y називається цільовою функцією, що залежить від параметрів(x1, x2, ..., xn) і в залежності від задачі прагне до максимального чи мінімального значення.
Для більшої наочності можна навести приклад великого підприємства, що виробляє певні товари і пов’язане з багатьма іншими підприємствами (постачальники сировини чи комплектуючих, збут продукції, маркетинг, гуртовий продаж, партнери). Діяльність підприємства залежить від багатьох факторів (параметрів), які можуть змінюватися в широкому або обмеженому діапазоні.
Нехай, ставиться завдання збільшити дохід компанії і знайти ті чинники і їх значення, що цьому сприятимуть. У цьому випадку цільовою функцією буде «Дохід компанії», що прямо чи опосередковано залежить від багатьох параметрів, таких як число працівників компанії, обсяг виробництва, витрати на рекламу, ціни на кінцеві продукти тощо. Ці параметри пов'язані між собою - наприклад, при зменшенні числа працівників швидше за все впаде й обсяг виробництва.
В даній постановці завданням є знайти таку комбінацію значень вхідних параметрів, щоб цільова функція була як можна максимальною.
Деякі задачі оптимізації (з невеликою кількістю параметрів та діапазону їх змін) легко розв’язати, але є і такі, точне рішення яких знайти практично неможливо (знайти максимальне значення цільової функції, що залежить від значної кількості параметрів з широким діапазоном значень).
Відомо два основні шляхи вирішення таких задач - переборний та градієнтний.
Переборний метод. Для пошуку оптимального рішення (максимум цільової функції) потрібно послідовно обчислити значення функції у всіх точках. Метод є простим, але потребує великої кількості обчислень і часу.
Градієнтний спуск. Обираються випадкові значення параметрів, які поступово змінюються, досягаючи найбільшої швидкості зросту цільової функції. Алгоритм може зупинитись, досягнувши локального оптимуму (максимуму чи мінімуму). Градієнтні методи швидкі, але не гарантують оптимального рішення (оскільки цільова функція має як глобальний оптимум так і декілька локальних оптимумів).
Ефективним способом вирішення задач оптимізації є природні алгоритми, що представляють комбінацію переборного та градієнтного методів. Тобто, якщо на деякій множині задано складну функцію від багатьох змінних, тоді природні алгоритми є програмами, які за визначений час знаходять точку, де значення функції знаходиться достатньо близько до максимально можливого значення, це буде одним з кращих рішень.
Для кращого розуміння природніх алгоритмів потрібно роз'яснити поняття поверхні станів цільової функції. Кожному значенню параметрів кількістю N відповідає один вимір в багатовимірному просторі. N+1-ий вимір відповідає значенню цільової функції. Для різноманітних сполучень значень параметрів відповідне значення цільової функції можна зобразити точкою в N+1-вимірному просторі. Всі ці точки утворюють деяку поверхню - поверхню станів. Метою використання природніх алгоритмів є знаходження на багатовимірній поверхні найвищої або найнижчої точки, що відповідатиме значенню цільової функції.
Поверхня станів має складну будову і досить неприємні властивості, зокрема, наявність локальних мінімумів (точки, найнижчі в своєму певному околі, але вищі від глобального мінімуму), пласкі ділянки, сідлові точки і довгі вузькі яри. Аналітичними засобами неможливо визначити розташування глобального мінімуму на поверхні станів, тому робота природніх алгоритмів полягає в дослідженні цієї поверхні.
Відштовхуючись від початкової конфігурації параметрів (від випадково обраної точки/точок на поверхні), алгоритми поступово відшукують глобальний оптимум (максимум чи мінімум) цільової функції. Обчислюється вектор напрямку та розмір кроків просування по поверхні з заданої точки (рис.5.1).
Рис.5.1. Наочний приклад пошуку глобального оптимуму
Алгоритми діють ітеративне, на кожній ітерації перевизначається знайдене значення цільової функції, що порівнюється з попередніми значеннями і обчислюється похибка. Значення похибки використовують для корекції певних коефіцієнтів (напрямок і довжина кроків просування по поверхні), і дії повторюються. Робота алгоритму припиняється або коли пройдена визначена кількість ітерацій, або коли похибка досягає визначеного рівня малості, або коли похибка перестає зменшуватись. Користувач переважно сам вибирає потрібний критерій припинення обчислень.
Зрештою алгоритм зупиняється в точці оптимуму, що може виявитись лише локальним оптимумом (в ідеальному випадку - глобальним).
Складність в алгоритмах полягає у виборі довжини кроків. При великій довжині кроку збіжність буде швидшою, але є небезпека перестрибнути рішення, або просуватися в невірному напрямку. При маленьких кроках, правильний напрямок буде виявлено, але зростає кількість ітерацій. На практиці розмір кроків береться пропорційним до крутизні схилу з деякою константою - швидкістю навчання. Правильний вибір швидкості навчання залежить від конкретної задачі і здійснюється дослідним шляхом. Ця константа може також залежати від часу, зменшуючись в міру просування алгоритму.
5.1.1. Основні терміни популяційних алгоритмів
В природніх алгоритмах для назви членів популяції використовується термін агент (agent). В різних популяційних алгоритмах агентів позначають термінами – особини, індивіди тощо.
Загальна схема популяційних алгоритмів містить наступні етапи:
Ініціалізація популяції. В області пошуку в різний спосіб розміщується певна кількість початкових наближень до шуканого рішення задачі - ініціалізація популяції агентів.
Міграція агентів популяції. За допомогою певного набору операторів переміщення, специфічних для кожного з популяційних алгоритмів, агенти в області пошуку переміщаються таким чином, щоб в кінцевому рахунку наблизитися до шуканого екстремуму цільової функції.
Завершення пошуку. Перевіряється виконання умов закінчення ітерацій, і якщо їх виконано, обчислення завершуються, приймаючи краще із знайдених станів агентів популяції за наближене рішення задачі. Якщо зазначені умови не виконано, етап 2 повторюється.
При ініціалізації популяції можуть бути використані детерміновані і випадкові алгоритми. Істотно скоротити час вирішення завдання може формування початкової популяції, агенти якої знаходяться поблизу глобального оптимуму цільової функції. Однак, зазвичай, апріорна інформація про місцезнаходження цього екстремуму є відсутньою, тому, агентів початкової популяції розподіляють рівномірно по всій області пошуку.
Як умову завершення пошуку використовують, як правило, досягнення заданого числа ітерацій (поколінь). Часто використовують також умову стагнації (stagnation) алгоритму, коли краще досягнуте значення цільової функції не змінюється протягом заданого числа ітерацій. Можуть бути використані й інші умови, наприклад, умова вичерпання часу, що відведено на вирішення завдання.
Більшість популяційних алгоритмів мають яскраво виражену модульну структуру, що дозволяє легко отримати велику кількість варіантів кожного з алгоритмів шляхом комбінування правил ініціалізації популяції, операторів переміщення і умов завершення пошуку.
Агентам популяції притаманні основні властивості.
Автономність - агенти пересуваються в просторі пошуку, зазвичай, незалежно один від одного.
Стохастичність - процес пересування агентів містить випадкову компоненту.
Обмеженість уявлення - кожен з агентів популяції має інформацію лише про частину області пошуку, в якій він просувається і, можливо, про оточення деяких інших агентів.
Децентралізація - відсутність агентів, які керують процесом пошуку в цілому.
Комунікабельність - агенти в різний спосіб можуть обмінюватися між собою інформацією про топологію (ландшафт) поверхні станів цільової функції, що виявлено в процесі дослідження своєї частини області пошуку.
Навіть, якщо стратегія поведінки кожного з агентів популяції досить проста, зазначені властивості агентів забезпечують формування колективного інтелекту, який проявляється в самоорганізації і складній поведінці популяції в цілому.
Еволюційні алгоритми
До них відносяться:
Генетичні алгоритми.
Еволюційні стратегії.
Генетичне програмування.
Еволюційне програмування.
Еволюційні алгоритми – це загальна назва алгоритмів пошуку, оптимізації або навчання, що засновані на принципах природного еволюційного процесу. Вони призначені для ітераційного пошуку бажаних рішень. На відміну від точних математичних методів еволюційні методи дозволяють за прийнятний час знаходити рішення, наближені до оптимальних та характеризуються меншою залежністю від особливостей завдання.
5.2. Генетичний алгоритм
Генетичний алгоритм - це евристичний алгоритм пошуку, який застосовується для вирішення завдань оптимізації, що нагадує біологічну еволюцію.
Еволюція - це процес постійної оптимізації біологічних видів. Еволюційна теорія стверджує, що життя на планеті виникло спочатку лише в найпростіших формах - у вигляді одноклітинних організмів. Ці форми поступово ускладнювалися, пристосовуючись до навколишнього середовища, породжуючи нові види, і через багато мільйонів років з'явилися перші тварини і люди. Кожен біологічний вид з часом вдосконалює свої якості, щоб ефективно справлятися з важливими задачами виживання, самозахисту, розмноження. Таким чином виникло захисне забарвлення в багатьох риб і комах, панцир у черепахи, отрута в скорпіона тощо.
За допомогою еволюції природа постійно оптимізує живі організми, знаходячи часом неординарні рішення, ґрунтуючись лише на двох біологічних механізмах - природного відбору і генетичного спадкування.
Природний відбір гарантує, що найбільш пристосовані особини надають більшу кількість нащадків, а завдяки генетичному спадкуванню частина нащадків не лише збереже високу пристосованість батьків, але буде мати і деякі нові властивості. Якщо нові властивості виявляються корисними, то з великою імовірністю вони перейдуть до наступного покоління. Таким чином, відбувається нагромадження корисних якостей і поступове підвищення пристосованості біологічного виду в цілому. Знаючи, як вирішується задача оптимізації видів у природі, можна застосувати схожий метод для вирішення реальних завдань.
Для ясного розуміння спадковості, потрібно дещо поглибитися в побудову природної клітини - у світ генів і хромосом. Майже в кожній клітині будь-якої особини є набір хромосом, що містять інформацію про цю особину. Основна частина хромосоми - нитка ДНК, яка визначає, які хімічні реакції будуть відбуватися в даній клітині, як вона буде розвиватися і які функції виконувати (рис.5.2).
Рис.5.2. Спрощене представлення складу хромосоми
В будь якому організмі присутні два види клітин: статеві (такі, як сперматозоїд і яйцеклітина) і соматичні.
Соматичні клітини містять 23 пари (46 хромосом): 22 пари нестатевих хромосом і одна пара статевих хромосом (Х і Y хромосоми). В кожній парі одна з хромосом отримана від батька, а друга - від матері (рис.5.3).
Рис. 5.3. Процес наслідування хромосом
В статевих клітинах хромосом лише 23, і вони непарні. При заплідненні відбувається об’єднання чоловічої і жіночої статевих клітин і утворюється клітина зародка, що містить саме 46 хромосом. Які властивості нащадок одержить від батька, а які - від матері? Це залежить від того, які саме статеві клітини брали участь у заплідненні.
При статевому розмноженні людини (мейоз) зливаються дві окремі статеві клітини, які продукують соматичну клітину. Чоловічі сперматозоїди містять один з двох типів статевих хромосом X або Y. Жіночі яйцеклітини містять тільки Х-хромосому. В цьому випадку клітина сперми визначає стать індивідуума. Якщо сперматозоїдна клітина, яка містить Х-хромосому, запліднює яйцеклітину, результуючою соматичною клітиною XX - жіноча стать. Якщо клітина сперми містить Y-хромосому, тоді результуючою буде XY - чоловіча стать.
Ген - це частина хромосоми (ланка ДНК), який відповідає за певну властивість особини, наприклад за колір очей, тип волосся, колір шкіри тощо. Вся сукупність генетичних ознак людини кодується за допомогою приблизно 60 тис. генів.
Парні хромосоми відповідають за однакові ознаки - наприклад, батьківська хромосома може містити ген чорного кольору око, а парна їй материнська - ген голубого кольору. Існують визначені закони, що керують участю тих чи інших генів у розвитку особини. Зокрема, у даному прикладі нащадок буде чорнооким, оскільки ген блакитних очей є "слабшим" і подавляється геном будь-якого іншого кольору.
Процес вироблення соматичних клітин в організмі піддається змінам, завдяки яким нащадки відрізняються від своїх батьків. Зокрема, відбувається наступне: парні хромосоми соматичної клітини зближаються впритул, потім їхні нитки ДНК розриваються в кількох випадкових місцях і хромосоми обмінюються своїми частинами (рис.5.4).
Рис.5.4. Спрощене представлення процесу схрещування
Цей процес забезпечує появу нових варіантів хромосом і зветься "кросовер" (crossover, crossingover або схрещування). Кожна з нових хромосом з'являється потім всередині однієї з статевих клітин, і її генетична інформація може реалізуватись в нащадках даної особини.
Важливим фактор, що впливає на спадковість є мутації, які виражаються в зміні деяких ділянок ДНК. Мутації є випадковими і можуть бути викликані різними зовнішніми факторами. Якщо мутація відбулася в статевій клітині, то змінений ген може передатися до нащадку і проявитися у вигляді нових властивостей. Саме мутації є причиною появи нових біологічних видів, а кросовер визначає вже змінність всередині виду.
Загальна ідея генетичного алгоритму
Генетичний алгоритм є методом багатовимірної оптимізації, тобто методом пошуку оптимуму багатовимірної функції. Потенційно цей метод можна використовувати для глобальної оптимізації, але з цим виникають складності. Суть методу полягає в моделюванні еволюційного процесу: є певна популяція (набір векторів), яка розмножується, на яку впливають мутації і проводиться природний відбір на підставі оптимізації цільової функції.
Отже, перш за все популяція повинна розмножуватися. Основний принцип розмноження - нащадок схожий на своїх батьків. Тобто потрібно задати механізм успадкування, що містить елемент випадковості. Швидкість розвитку таких систем дуже низька – генетична різноманітність зменшується, популяція вироджується. Тобто значення функції перестає мінімізуватися.
Для вирішення цієї проблеми використовується механізм мутації, який полягає в випадковій зміні випадкових особин. Цей механізм дозволяє ввести щось нове в генетичну різноманітність.
Наступний важливий механізм - селекція - відбір особин, які краще оптимізують функцію. Зазвичай, відбирають стільки особин, скільки було до розмноження, щоб в кожній епосі була постійна кількість особин в популяції. Також прийнято відбирати випадкових особин, які, можливо, погано оптимізують функцію, але зате вносять різноманітність в наступні покоління.
Цих трьох механізмів може забракнути, щоб мінімізувати функцію. Так популяція вироджується - рано чи пізно популяція може застрягнути в локальному оптимумі. Коли таке відбувається, проводять процес, званий струсом (в природі аналогії - глобальні катаклізми), коли знищується майже вся популяція, і вводяться нові (випадкові) особини.
Це опис класичного генетичного алгоритму, він простий в реалізації і є місце для фантазії і досліджень.
Практичний приклад генетичного алгоритму
Для того, щоб говорити про генетичне спадкування, потрібно наділити особини хромосомами. В генетичному алгоритмі хромосома - це числовий вектор набору параметрів, що сприяють вирішенню задачі. Які саме вектори варто розглядати в конкретній задачі, вирішує користувач. Кожна з позицій вектору хромосоми називається геном і відповідає за певний вхідний параметр.
Наприклад, в завданні знайти найкращі рішення для збільшення прибутків від діяльності компанії цільовою функцією буде «Дохід компанії», що прагне до максимуму і залежить від певних чинників
Дохід компанії = f («собівартість продукції», «витратні матеріали», «заробітна платня», «амортизаційні витрати», …)
В термінах генетичного алгоритму «Дохід компанії» є хромосомою. Чинники, що впливають на цільову функцію будуть розглядатися як гени («собівартість продукції», «витратні матеріали», «заробітна платня», «амортизаційні витрати»). Тоді хромосоми «Дохід компанії» можна представити як набір генів. Кожен ген, що відповідає за певний чинник може містити різні значення.
Хромосома 1 – 15, 200, 5000, 100
Хромосома n – 12, 260, 3800, 112
Зазвичай для спрощення обчислень в генетичних алгоритмах кожен ген представлено у двійковому коді
Хромосома 1 – 10001111000 00001001000 10001111100 11101111011
Хромосома n – 10101101100 01101001011 10110011100 11101001000
В загальному роботу генетичного алгоритму можна описати основними етапами (рис.4.5).
1. Генерація початкової популяції, що складається з особин, вибраних випадковим чином.
2. Для кожної особини алгоритм обчислює ймовірність Ps(i), яка дорівнює відношенню її пристосованості до сумарної пристосованості популяції:
3. Відповідно до величини Ps(і) відбувається відбір найсильніших n особин для подальшої генетичної обробки. Члени популяції з високою пристосованістю будуть вибиратися з більшою імовірністю, ніж особини з низькою пристосованістю.
4. Після відбору, n обраних особин випадковим чином поділяються на n/2 пари, які будуть схрещуватися між собою.
5. Для кожної пари застосовується схрещування (кросовер). Кросовер - це операція, при якій із двох хромосом породжується кілька нових хромосом. Для одноточкового кросоверу випадковим образом вибирається точка розриву (ділянка між сусідніми ланками в рядку). Обидві батьківські структури розриваються на два сегменти в цій точці. Потім, відповідні сегменти різних батьків склеюються і виходять два генотипи нащадків.
Наприклад, припустимо, один батько складається з 10 нулів, а інший - з 10 одиниць. Нехай з 9 можливих точок розриву обрано точку 3. Нижче представлено батьківські особини та утворені їхні нащадки.
Батько 1 0000000000 000
0000000--> 111
0000000 1110000000 Нащадок 1Тема 5. Природні алгоритми
Всі алгоритми, що натхненні живою природою відносяться до класу евристичних алгоритмів (Heuristic Algorithms), тобто алгоритмів, для яких збіжність до глобального вирішення не є доведеною, але експериментально встановлено, що в більшості випадків вони дають досить гарне рішення.
Дослідження, що відбуваються у цьому напрямку можна умовно поділити на
Природні моделі. Це системи, які відтворюють біологічні популяції або системи і не є корисними в прикладному сенсі. Природні моделі відтворюють розвиток біологічних системи, мають складну поведінку і зазвичай не використовуються для вирішення технічних завдань. До цих систем відносять так зване «штучне життя».
Природні алгоритми. Це системи, які використовують та моделюють біологічні принципи діяльності та розвитку популяції. Вони успішно використовуються для завдань евристичного пошуку, оптимізації і можуть легко бути описані математичною мовою. Дані інтелектуальні алгоритми часто називають популяційними або поведінковими. Популярними для вирішення різного типу завдань є:
Еволюційні алгоритми (генетичний алгоритм та еволюційні стратегії).
Алгоритми колективної поведінки (мурашиний алгоритм).
Алгоритми ройового інтелекту (алгоритм рою частинок, бджолиний алгоритм тощо)
Алгоритми колективної діяльності людей (наприклад, алгоритм еволюції розуму).
Інші алгоритми, що запозичені з живої та неживої природи.
5.1. Постановка задачі оптимізації
У найпростішому випадку задача оптимізації полягає у знаходженні екстремуму (мінімуму або максимуму) цільової функції шляхом систематичного перебору вхідних значень з дозволеного набору та обчислення її значення.
Y= f(x1, x2, ..., xn)
Y називається цільовою функцією, що залежить від параметрів(x1, x2, ..., xn) і в залежності від задачі прагне до максимального чи мінімального значення.
Для більшої наочності можна навести приклад великого підприємства, що виробляє певні товари і пов’язане з багатьма іншими підприємствами (постачальники сировини чи комплектуючих, збут продукції, маркетинг, гуртовий продаж, партнери). Діяльність підприємства залежить від багатьох факторів (параметрів), які можуть змінюватися в широкому або обмеженому діапазоні.
Нехай, ставиться завдання збільшити дохід компанії і знайти ті чинники і їх значення, що цьому сприятимуть. У цьому випадку цільовою функцією буде «Дохід компанії», що прямо чи опосередковано залежить від багатьох параметрів, таких як число працівників компанії, обсяг виробництва, витрати на рекламу, ціни на кінцеві продукти тощо. Ці параметри пов'язані між собою - наприклад, при зменшенні числа працівників швидше за все впаде й обсяг виробництва.
В даній постановці завданням є знайти таку комбінацію значень вхідних параметрів, щоб цільова функція була як можна максимальною.
Деякі задачі оптимізації (з невеликою кількістю параметрів та діапазону їх змін) легко розв’язати, але є і такі, точне рішення яких знайти практично неможливо (знайти максимальне значення цільової функції, що залежить від значної кількості параметрів з широким діапазоном значень).
Відомо два основні шляхи вирішення таких задач - переборний та градієнтний.
Переборний метод. Для пошуку оптимального рішення (максимум цільової функції) потрібно послідовно обчислити значення функції у всіх точках. Метод є простим, але потребує великої кількості обчислень і часу.
Градієнтний спуск. Обираються випадкові значення параметрів, які поступово змінюються, досягаючи найбільшої швидкості зросту цільової функції. Алгоритм може зупинитись, досягнувши локального оптимуму (максимуму чи мінімуму). Градієнтні методи швидкі, але не гарантують оптимального рішення (оскільки цільова функція має як глобальний оптимум так і декілька локальних оптимумів).
Ефективним способом вирішення задач оптимізації є природні алгоритми, що представляють комбінацію переборного та градієнтного методів. Тобто, якщо на деякій множині задано складну функцію від багатьох змінних, тоді природні алгоритми є програмами, які за визначений час знаходять точку, де значення функції знаходиться достатньо близько до максимально можливого значення, це буде одним з кращих рішень.
Для кращого розуміння природніх алгоритмів потрібно роз'яснити поняття поверхні станів цільової функції. Кожному значенню параметрів кількістю N відповідає один вимір в багатовимірному просторі. N+1-ий вимір відповідає значенню цільової функції. Для різноманітних сполучень значень параметрів відповідне значення цільової функції можна зобразити точкою в N+1-вимірному просторі. Всі ці точки утворюють деяку поверхню - поверхню станів. Метою використання природніх алгоритмів є знаходження на багатовимірній поверхні найвищої або найнижчої точки, що відповідатиме значенню цільової функції.
Поверхня станів має складну будову і досить неприємні властивості, зокрема, наявність локальних мінімумів (точки, найнижчі в своєму певному околі, але вищі від глобального мінімуму), пласкі ділянки, сідлові точки і довгі вузькі яри. Аналітичними засобами неможливо визначити розташування глобального мінімуму на поверхні станів, тому робота природніх алгоритмів полягає в дослідженні цієї поверхні.
Відштовхуючись від початкової конфігурації параметрів (від випадково обраної точки/точок на поверхні), алгоритми поступово відшукують глобальний оптимум (максимум чи мінімум) цільової функції. Обчислюється вектор напрямку та розмір кроків просування по поверхні з заданої точки (рис.5.1).
Рис.5.1. Наочний приклад пошуку глобального оптимуму
Алгоритми діють ітеративне, на кожній ітерації перевизначається знайдене значення цільової функції, що порівнюється з попередніми значеннями і обчислюється похибка. Значення похибки використовують для корекції певних коефіцієнтів (напрямок і довжина кроків просування по поверхні), і дії повторюються. Робота алгоритму припиняється або коли пройдена визначена кількість ітерацій, або коли похибка досягає визначеного рівня малості, або коли похибка перестає зменшуватись. Користувач переважно сам вибирає потрібний критерій припинення обчислень.
Зрештою алгоритм зупиняється в точці оптимуму, що може виявитись лише локальним оптимумом (в ідеальному випадку - глобальним).
Складність в алгоритмах полягає у виборі довжини кроків. При великій довжині кроку збіжність буде швидшою, але є небезпека перестрибнути рішення, або просуватися в невірному напрямку. При маленьких кроках, правильний напрямок буде виявлено, але зростає кількість ітерацій. На практиці розмір кроків береться пропорційним до крутизні схилу з деякою константою - швидкістю навчання. Правильний вибір швидкості навчання залежить від конкретної задачі і здійснюється дослідним шляхом. Ця константа може також залежати від часу, зменшуючись в міру просування алгоритму.
5.1.1. Основні терміни популяційних алгоритмів
В природніх алгоритмах для назви членів популяції використовується термін агент (agent). В різних популяційних алгоритмах агентів позначають термінами – особини, індивіди тощо.
Загальна схема популяційних алгоритмів містить наступні етапи:
Ініціалізація популяції. В області пошуку в різний спосіб розміщується певна кількість початкових наближень до шуканого рішення задачі - ініціалізація популяції агентів.
Міграція агентів популяції. За допомогою певного набору операторів переміщення, специфічних для кожного з популяційних алгоритмів, агенти в області пошуку переміщаються таким чином, щоб в кінцевому рахунку наблизитися до шуканого екстремуму цільової функції.
Завершення пошуку. Перевіряється виконання умов закінчення ітерацій, і якщо їх виконано, обчислення завершуються, приймаючи краще із знайдених станів агентів популяції за наближене рішення задачі. Якщо зазначені умови не виконано, етап 2 повторюється.
При ініціалізації популяції можуть бути використані детерміновані і випадкові алгоритми. Істотно скоротити час вирішення завдання може формування початкової популяції, агенти якої знаходяться поблизу глобального оптимуму цільової функції. Однак, зазвичай, апріорна інформація про місцезнаходження цього екстремуму є відсутньою, тому, агентів початкової популяції розподіляють рівномірно по всій області пошуку.
Як умову завершення пошуку використовують, як правило, досягнення заданого числа ітерацій (поколінь). Часто використовують також умову стагнації (stagnation) алгоритму, коли краще досягнуте значення цільової функції не змінюється протягом заданого числа ітерацій. Можуть бути використані й інші умови, наприклад, умова вичерпання часу, що відведено на вирішення завдання.
Більшість популяційних алгоритмів мають яскраво виражену модульну структуру, що дозволяє легко отримати велику кількість варіантів кожного з алгоритмів шляхом комбінування правил ініціалізації популяції, операторів переміщення і умов завершення пошуку.
Агентам популяції притаманні основні властивості.
Автономність - агенти пересуваються в просторі пошуку, зазвичай, незалежно один від одного.
Стохастичність - процес пересування агентів містить випадкову компоненту.
Обмеженість уявлення - кожен з агентів популяції має інформацію лише про частину області пошуку, в якій він просувається і, можливо, про оточення деяких інших агентів.
Децентралізація - відсутність агентів, які керують процесом пошуку в цілому.
Комунікабельність - агенти в різний спосіб можуть обмінюватися між собою інформацією про топологію (ландшафт) поверхні станів цільової функції, що виявлено в процесі дослідження своєї частини області пошуку.
Навіть, якщо стратегія поведінки кожного з агентів популяції досить проста, зазначені властивості агентів забезпечують формування колективного інтелекту, який проявляється в самоорганізації і складній поведінці популяції в цілому.
Еволюційні алгоритми
До них відносяться:
Генетичні алгоритми.
Еволюційні стратегії.
Генетичне програмування.
Еволюційне програмування.
Еволюційні алгоритми – це загальна назва алгоритмів пошуку, оптимізації або навчання, що засновані на принципах природного еволюційного процесу. Вони призначені для ітераційного пошуку бажаних рішень. На відміну від точних математичних методів еволюційні методи дозволяють за прийнятний час знаходити рішення, наближені до оптимальних та характеризуються меншою залежністю від особливостей завдання.
5.2. Генетичний алгоритм
Генетичний алгоритм - це евристичний алгоритм пошуку, який застосовується для вирішення завдань оптимізації, що нагадує біологічну еволюцію.
Еволюція - це процес постійної оптимізації біологічних видів. Еволюційна теорія стверджує, що життя на планеті виникло спочатку лише в найпростіших формах - у вигляді одноклітинних організмів. Ці форми поступово ускладнювалися, пристосовуючись до навколишнього середовища, породжуючи нові види, і через багато мільйонів років з'явилися перші тварини і люди. Кожен біологічний вид з часом вдосконалює свої якості, щоб ефективно справлятися з важливими задачами виживання, самозахисту, розмноження. Таким чином виникло захисне забарвлення в багатьох риб і комах, панцир у черепахи, отрута в скорпіона тощо.
За допомогою еволюції природа постійно оптимізує живі організми, знаходячи часом неординарні рішення, ґрунтуючись лише на двох біологічних механізмах - природного відбору і генетичного спадкування.
Природний відбір гарантує, що найбільш пристосовані особини надають більшу кількість нащадків, а завдяки генетичному спадкуванню частина нащадків не лише збереже високу пристосованість батьків, але буде мати і деякі нові властивості. Якщо нові властивості виявляються корисними, то з великою імовірністю вони перейдуть до наступного покоління. Таким чином, відбувається нагромадження корисних якостей і поступове підвищення пристосованості біологічного виду в цілому. Знаючи, як вирішується задача оптимізації видів у природі, можна застосувати схожий метод для вирішення реальних завдань.
Для ясного розуміння спадковості, потрібно дещо поглибитися в побудову природної клітини - у світ генів і хромосом. Майже в кожній клітині будь-якої особини є набір хромосом, що містять інформацію про цю особину. Основна частина хромосоми - нитка ДНК, яка визначає, які хімічні реакції будуть відбуватися в даній клітині, як вона буде розвиватися і які функції виконувати (рис.5.2).
Рис.5.2. Спрощене представлення складу хромосоми
В будь якому організмі присутні два види клітин: статеві (такі, як сперматозоїд і яйцеклітина) і соматичні.
Соматичні клітини містять 23 пари (46 хромосом): 22 пари нестатевих хромосом і одна пара статевих хромосом (Х і Y хромосоми). В кожній парі одна з хромосом отримана від батька, а друга - від матері (рис.5.3).
Рис. 5.3. Процес наслідування хромосом
В статевих клітинах хромосом лише 23, і вони непарні. При заплідненні відбувається об’єднання чоловічої і жіночої статевих клітин і утворюється клітина зародка, що містить саме 46 хромосом. Які властивості нащадок одержить від батька, а які - від матері? Це залежить від того, які саме статеві клітини брали участь у заплідненні.
При статевому розмноженні людини (мейоз) зливаються дві окремі статеві клітини, які продукують соматичну клітину. Чоловічі сперматозоїди містять один з двох типів статевих хромосом X або Y. Жіночі яйцеклітини містять тільки Х-хромосому. В цьому випадку клітина сперми визначає стать індивідуума. Якщо сперматозоїдна клітина, яка містить Х-хромосому, запліднює яйцеклітину, результуючою соматичною клітиною XX - жіноча стать. Якщо клітина сперми містить Y-хромосому, тоді результуючою буде XY - чоловіча стать.
Ген - це частина хромосоми (ланка ДНК), який відповідає за певну властивість особини, наприклад за колір очей, тип волосся, колір шкіри тощо. Вся сукупність генетичних ознак людини кодується за допомогою приблизно 60 тис. генів.
Парні хромосоми відповідають за однакові ознаки - наприклад, батьківська хромосома може містити ген чорного кольору око, а парна їй материнська - ген голубого кольору. Існують визначені закони, що керують участю тих чи інших генів у розвитку особини. Зокрема, у даному прикладі нащадок буде чорнооким, оскільки ген блакитних очей є "слабшим" і подавляється геном будь-якого іншого кольору.
Процес вироблення соматичних клітин в організмі піддається змінам, завдяки яким нащадки відрізняються від своїх батьків. Зокрема, відбувається наступне: парні хромосоми соматичної клітини зближаються впритул, потім їхні нитки ДНК розриваються в кількох випадкових місцях і хромосоми обмінюються своїми частинами (рис.5.4).
Рис.5.4. Спрощене представлення процесу схрещування
Цей процес забезпечує появу нових варіантів хромосом і зветься "кросовер" (crossover, crossingover або схрещування). Кожна з нових хромосом з'являється потім всередині однієї з статевих клітин, і її генетична інформація може реалізуватись в нащадках даної особини.
Важливим фактор, що впливає на спадковість є мутації, які виражаються в зміні деяких ділянок ДНК. Мутації є випадковими і можуть бути викликані різними зовнішніми факторами. Якщо мутація відбулася в статевій клітині, то змінений ген може передатися до нащадку і проявитися у вигляді нових властивостей. Саме мутації є причиною появи нових біологічних видів, а кросовер визначає вже змінність всередині виду.
Загальна ідея генетичного алгоритму
Генетичний алгоритм є методом багатовимірної оптимізації, тобто методом пошуку оптимуму багатовимірної функції. Потенційно цей метод можна використовувати для глобальної оптимізації, але з цим виникають складності. Суть методу полягає в моделюванні еволюційного процесу: є певна популяція (набір векторів), яка розмножується, на яку впливають мутації і проводиться природний відбір на підставі оптимізації цільової функції.
Отже, перш за все популяція повинна розмножуватися. Основний принцип розмноження - нащадок схожий на своїх батьків. Тобто потрібно задати механізм успадкування, що містить елемент випадковості. Швидкість розвитку таких систем дуже низька – генетична різноманітність зменшується, популяція вироджується. Тобто значення функції перестає мінімізуватися.
Для вирішення цієї проблеми використовується механізм мутації, який полягає в випадковій зміні випадкових особин. Цей механізм дозволяє ввести щось нове в генетичну різноманітність.
Наступний важливий механізм - селекція - відбір особин, які краще оптимізують функцію. Зазвичай, відбирають стільки особин, скільки було до розмноження, щоб в кожній епосі була постійна кількість особин в популяції. Також прийнято відбирати випадкових особин, які, можливо, погано оптимізують функцію, але зате вносять різноманітність в наступні покоління.
Цих трьох механізмів може забракнути, щоб мінімізувати функцію. Так популяція вироджується - рано чи пізно популяція може застрягнути в локальному оптимумі. Коли таке відбувається, проводять процес, званий струсом (в природі аналогії - глобальні катаклізми), коли знищується майже вся популяція, і вводяться нові (випадкові) особини.
Це опис класичного генетичного алгоритму, він простий в реалізації і є місце для фантазії і досліджень.
Практичний приклад генетичного алгоритму
Для того, щоб говорити про генетичне спадкування, потрібно наділити особини хромосомами. В генетичному алгоритмі хромосома - це числовий вектор набору параметрів, що сприяють вирішенню задачі. Які саме вектори варто розглядати в конкретній задачі, вирішує користувач. Кожна з позицій вектору хромосоми називається геном і відповідає за певний вхідний параметр.
Наприклад, в завданні знайти найкращі рішення для збільшення прибутків від діяльності компанії цільовою функцією буде «Дохід компанії», що прагне до максимуму і залежить від певних чинників
Дохід компанії = f («собівартість продукції», «витратні матеріали», «заробітна платня», «амортизаційні витрати», …)
В термінах генетичного алгоритму «Дохід компанії» є хромосомою. Чинники, що впливають на цільову функцію будуть розглядатися як гени («собівартість продукції», «витратні матеріали», «заробітна платня», «амортизаційні витрати»). Тоді хромосоми «Дохід компанії» можна представити як набір генів. Кожен ген, що відповідає за певний чинник може містити різні значення.
Хромосома 1 – 15, 200, 5000, 100
Хромосома n – 12, 260, 3800, 112
Зазвичай для спрощення обчислень в генетичних алгоритмах кожен ген представлено у двійковому коді
Хромосома 1 – 10001111000 00001001000 10001111100 11101111011
Хромосома n – 10101101100 01101001011 10110011100 11101001000
В загальному роботу генетичного алгоритму можна описати основними етапами (рис.4.5).
1. Генерація початкової популяції, що складається з особин, вибраних випадковим чином.
2. Для кожної особини алгоритм обчислює ймовірність Ps(i), яка дорівнює відношенню її пристосованості до сумарної пристосованості популяції:
3. Відповідно до величини Ps(і) відбувається відбір найсильніших n особин для подальшої генетичної обробки. Члени популяції з високою пристосованістю будуть вибиратися з більшою імовірністю, ніж особини з низькою пристосованістю.
4. Після відбору, n обраних особин випадковим чином поділяються на n/2 пари, які будуть схрещуватися між собою.
5. Для кожної пари застосовується схрещування (кросовер). Кросовер - це операція, при якій із двох хромосом породжується кілька нових хромосом. Для одноточкового кросоверу випадковим образом вибирається точка розриву (ділянка між сусідніми ланками в рядку). Обидві батьківські структури розриваються на два сегменти в цій точці. Потім, відповідні сегменти різних батьків склеюються і виходять два генотипи нащадків.
Наприклад, припустимо, один батько складається з 10 нулів, а інший - з 10 одиниць. Нехай з 9 можливих точок розриву обрано точку 3. Нижче представлено батьківські особини та утворені їхні нащадки.
Батько 1 0000000000 000
Батько 2 1111111111 111
6. Відповідно до алгоритму випадково обрані особини піддаються мутації. Мутація - це перетворення хромосоми, яке випадково змінює одну чи декілька її позицій (генів). Поширеним видом мутацій є випадкова зміна лише одного гену з хромосоми. В особині, що піддається мутації, випадковий біт з імовірністю Pm змінюється на протилежний.
7. В утвореній популяції відбувається обчислення пристосованості особин (п.1) і обираються найсильніші. Отримана популяція заміняє поточну і цикл одного покоління завершується.
Наступні покоління обробляються подібним чином: відбір, кросовер і мутація. В кожному наступному поколінні продукуються нові рішення, серед яких будуть як погані, так і хороші, але завдяки відбору число прийнятних рішень буде зростати.
Робота генетичного алгоритму є ітераційним процесом, що продовжується, доки не виконається задане число поколінь або інший критерій зупинки. Таким критерієм може бути:
Знаходження глобального або кращого локального рішення.
Вичерпання числа поколінь, що відведено на еволюцію.
Вичерпання часу, що відведено на еволюцію.
Наочний приклад
Нехай задано рівняння: a + 2b + 3c + 4d = 30
Задаємо, що вирішення цього рівняння знаходиться на відрізку [1; 30] (обмеження в 30 взято спеціально для спрощення завдання). Для формування популяції хромосом беремо 5 випадкових значень a, b, c, d.
Початкова популяція виглядатиме так:
Хр1 (1,28,15,3)
Хр2 (14,9,2,4)
Хр3 (13,5,7,3)
Хр4 (23,8,16,19)
Хр5 (9,13,5,2)
Для того щоб обчислити коефіцієнти виживання, підставимо кожне рішення у вираз. Відстань від отриманого значення до 30 і буде потрібним значенням.
Хр1 | 114-30 | = 84
Хр2 | 54-30 | = 24
Хр3 | 56-30 | = 26
Хр4 | 163-30 | = 133
Хр5 | 58-30 | = 28
Середня пристосованість (fitness) популяції дорівнює (84+24+26+133+28)/5=59.4.
Обчислюємо пристосованість кожної особини
Хр1 (84/59.4) = 1,4141
Хр2 (24/59.4) = 0,4040
Хр3 (26/59.4) = 0,4377
Хр4 (133/59.4) = 2,2390
Хр5 (28/59.4) = 0,4713
Обчислимо ймовірність вибору кожної хромосоми для кросовера та продукування нових хромосом. Рішення полягає в тому, щоб взяти суму зворотних значень коефіцієнтів, і виходячи з цього обчислювати відсотки.
Обчислюємо коефіцієнт виживання всієї популяції
1/84+1/24+1/26+1/133+1/28=0.135266
Обчислюємо коефіцієнт виживання кожної особини
Хр1 (1/84) /0.135266 = 8.80%
Хр2 (1/24) /0.135266 = 30.8%
Хр3 (1/26) /0.135266 = 28.4%
Хр4 (1/133) /0.135266 = 5.56%
Хр5 (1/28) /0.135266 = 26.4%
Значення, які є ближчими до 30 будуть більш бажаними і тому мають високий коефіцієнт виживання. Натомість, значення, які є далекими від 30 матимуть менший коефіцієнт виживання і відповідно меншу ймовірність у подальших обчисленнях.
Далі будемо вибирати п'ять пар батьків, у яких буде рівно по одній дитині. Надавати це право будемо давати рівно п'ять разів, кожен раз шанс стати батьком буде однаковим і буде дорівнює шансу на виживання.
Хр3-Хр1, Хр5-Хр2, Хр3-Хр5, Хр2-Хр5, Хр5-Хр3
Нащадок містить інформацію про гени батька і матері. Це можна забезпечити різними способами, але в даному випадку буде використовуватися «кросовер». (| = Розділова лінія)
Х.-батько: a1 | b1, c1, d1
Х.-матір: a2 | b2, c2, d2
Х.-нащадок: a1, b2, c2, d2 або a2, b1, c1, d1
Х.-батько: a1, b1 | c1, d1
Х.-матір: a2, b2 | c2, d2
Х.-нащадок: a1, b1, c2, d2 або a2, b2, c1, d1
Х.-батько: a1, b1, c1 | d1
Х.-матір: a2, b2, c2 | d2
Х.-нащадок: a1, b1, c1, d2 або a2, b2, c2, d1
Є багато шляхів передачі інформації нащадкові, кросовер - тільки один з багатьох. Розташування точки розриву може бути абсолютно довільним, як і те, які частини будуть отримані від батька чи матері.
У даному прикладі це виглядатиме так:
Х.-батько: (13 | 5,7,3)
Х.-матір: (1 | 28,15,3)
Х.-нащадок: (13,28,15,3)
Х.-батько: (9,13 | 5,2)
Х.-матір: (14,9 | 2,4)
Х.-нащадок: (9,13,2,4)
Х.-батько: (13,5,7 | 3)
Х.-матір: (9,13,5 | 2)
Х.-нащадок: (13,5,7,2)
Х.-батько: (14 | 9,2,4)
Х.-матір: (9 | 13,5,2)
Х.-нащадок: (14,13,5,2)
Х.-батько: (13,5 | 7, 3)
Х.-матір: (9,13 | 5, 2)
Х.-нащадок: (13,5,5,2)
Обчислимо коефіцієнти виживання нащадків.
Нщ1 (13,28,15,3) | 126-30 | = 96
Нщ2 (9,13,2,4) | 57-30 | = 27
Нщ3 (13,5,7,2) | 57-30 | = 22
Нщ4 (14,13,5,2) | 63-30 | = 33
Нщ5 (13,5,5,2) | 46-30 | = 16
Середня пристосованість (fitness) нащадків виявилася (96+27+22+33+16)/5=38.8, а у батьків цей коефіцієнт дорівнював (84+24+26+133+28)/5=59.4. Саме в цей момент доцільно використати мутацію, для цього слід замінити одне або більше значень на випадкове число від 1 до 30.
Алгоритм буде працювати до тих, пір, поки коефіцієнт виживання особин не стане дорівнювати нулю. Тобто буде знайдене рішення рівняння. Системи з більшою популяцією (наприклад, 50 замість 5-й сходяться до бажаного рівня (0) більш швидко і стабільно.
Модифікації
Дослідники генетичних алгоритмів пропонують багато інших операторів відбору, кросоверу і мутації. Наприклад:
Двохточковий і рівномірний кросовер – альтернативи для одноточкового оператора. В двохточковому кросинговері вибираються дві точки розриву, і батьківські хромосоми обмінюються сегментом, що знаходиться між двома цими точками. У рівномірному кросинговері, кожен біт першого батька успадковується першим нащадком із заданою імовірністю; у противному випадку цей біт передається до другого нащадку. І навпаки.
Недоліки у порівнянні з іншими методами оптимізації:
Пошук оптимального рішення для складної задачі високої розмірності часто вимагає великих витрат. В реальних задачах обчислення можуть тривати від кількох годин до кількох днів.
Генетичні алгоритми погано масштабуються під складність вирішуваної проблеми. При збільшенні області пошуку рішень збільшується число елементів, що піддаються до обробки.
Умови зупинки алгоритму є різними для кожної проблеми.
В багатьох завданнях генетичні алгоритми мають тенденцію сходитися до локального оптимуму замість глобального оптимуму для даної задачі.
5.3. Еволюційні стратегії
Серед стратегій, що використовуються в сучасних генетичних алгоритмах, можна виділити стратегії елітізма, різноманіття, "свіжої крові", зміни розміру популяції, паралельні еволюції (міграції, турнірна).
Самою поширеною є стратегія елітизму, коли на всіх етапах еволюційного процесу зберігається елітна група з кращих особин популяції. Вважається, що краща особина містить корисний генетичний матеріал, який може бути використаний для пошуку оптимуму. Таким чином, використання стратегії елітізму запобігає можливості видалення з популяції кращих особин при формуванні нового покоління.
Розмір елітної групи визначається особливостями алгоритму і залежить, як правило, від загальної чисельності популяції. В процесі роботи алгоритму потрібно стежити, щоб особини елітної групи не виродились в однакові або подібні генотопи.
Використання стратегії різноманіття вирішує проблему утворення в популяції множини однакових або подібних осіб. Ці особини звужують область пошуку рішення та приводять до більш сильного виродження наступних поколінь.
Технічно дана стратегія реалізується на кожному етапі еволюційного процесу попарним оцінюванням ступеня близькості всіх особин. Якщо між кількома особинами є подібність, яка оцінюється нижче за деяке задане порогове значення, з них залишається тільки одна особина (краща). Вакантні місця заповнюються нащадками, що отримані на поточній стадії еволюції або, за необхідності, новими випадковими рішеннями.
Стратегія "свіжої крові" полягає у введенні в нове покоління популяції певної кількості нових, випадково отриманих особин замість групи батьківських. Процедура може виконуватися систематично з заданим інтервалом між поколіннями або випадково на будь-якій стадії еволюції. Стратегія «свіжого крові» не повинна вступати в протиріччя з стратегією елітізма, тому, серед вилучених батьківських особин не повинно бути елітних.
Стратегія зміни розміру популяції передбачає нестабільність кількості особин, що беруть участь у процесі на кожній стадії еволюції. Кількість особин змінюється залежно від якісних характеристик популяції в цілому. Цими характеристиками можуть бути середня пристосованість або її зміна протягом певної кількості стадій еволюції.
Наприклад, при підвищенні середньої пристосованості популяції або динаміки її зміни об'єм популяції зростає. Відповідно, при погіршенні - зменшується. Незалежно від правила зміни розміру популяції, повинні бути встановлені нижня і верхня межі, а також початкова кількість особин.
Стратегії паралельних еволюцій (міграційна, турнірна) скеровані на формування незалежних або обмежено залежних груп, всередині яких протікає еволюційний процес. В кожній групі можуть застосовуватися власні налаштування генетичного алгоритму, що може сприяти знаходженню кращого рішення. В подальшому відбувається перенесення генетичної інформації з однієї групи в іншу або їх об'єднання.
При реалізації стратегії міграції вся популяція поділяється на кілька груп, зазвичай, з різною кількістю особин. Оператори кросоверу застосовуються до особин строго зі своїх спільнот. До окремих особин застосовуються різні оператори мутації і інверсії. Процеси еволюції відбуваються незалежно, кожна в своїй групі. І лише в деяких випадках (з невеликою ймовірністю) відбувається обмін генетичним матеріалом окремих особин між групами. Протягом еволюції збирається банк кращих рішень, які потім об'єднуються в єдину популяцію. Для популяції кращих рішень реалізується свій еволюційний процес.
Турнірна стратегія передбачає проведення повністю незалежних закінчених еволюційних процесів в кількох групах і об'єднання отриманих в кожній групі кращих рішень в одну або кілька нових груп з виконанням наступного етапу еволюції. Кількість таких етапів в загальному випадку може бути довільною і обмежується лише вимогами часу і обчислювальними можливостями. Природно, чим більше етапів, тим більша ймовірність знаходження глобального оптимуму. Розміри груп також можуть бути різними: від кількох десятків до кількох одиниць особин.
5.4. Генетичне програмування
Генетичне програмування - це методика машинного навчання. У загальному випадку обчислення починаються з великого набору програм (популяції), згенерованих випадковим чином або написаних вручну, про які відомо, що це досить хороші рішення. Ці програми конкурують між собою в спробі вирішити поставлене користувачем завдання. Це може бути гра, в якій програми безпосередньо змагаються між собою, або спеціальний тест, що визначає, яка програма краще. По завершенні змагання складається посортований список програм - від найкращої до найгіршої.
Далі вступає в справу еволюція - найкращі програми копіюються і модифікуються в один з двох способів. Найпростішим є мутація: деякі частини програми випадковим чином і незначно змінюються в надії, що від цього рішення стане краще (рис.5.6).

Рис.5.6. Алгоритм генетичного програмування
Інший спосіб є схрещуванням – пара відібраних програм обмінюються своїми частинами. Частина однієї з відібраних програм переміщається в іншу. В результаті процедури копіювання та модифікації створюється багато нових програм, які засновані на найкращих зразках попередньої популяції, але не збігаються з ними.
На кожному етапі якість програм обчислюється за допомогою функції пристосованості (Fitness Function). Оскільки розмір популяції не змінюється, програми, які виявилися гіршими, видаляються з популяції, звільняючи місце для нових.
Створюється нова популяція і весь процес повторюється. Оскільки зберігаються і змінюються самі кращі програми, то є сподівання, що з кожним поколінням вони будуть вдосконалюватися. Нові покоління створюються, доки не буде виконано умову завершення, яка в залежності від завдання може формулюватися в один з способів:
Знайдено ідеальне рішення.
Знайдено достатньо хороше рішення.
Кількість поколінь досягло заданої межі.
Рішення не вдається поліпшити протягом кількох поколінь.
5.5. Еволюційне програмування
Еволюційне програмування було запропоновано Лоуренсом Дж. Фогелем в 1960 році. У той час штучний інтелект було обмежено двома основними напрямками досліджень: моделюванням людського мозку (нейронні мережі) і моделюванням поведінки людини (евристичне програмування). Альтернативний варіант Фогеля був спрямований на моделювання процесу еволюції, як засобу отримання розумної поведінки. Фогель розглядає інтелект як складову частину здатності робити передбачення відповідно до заданої мети. На його думку прогнозування є необхідною умовою для розумної поведінки.
Гіпотези про вид залежності цільової змінної від інших змінних формулюються системою у вигляді програм. Процес побудови таких програм розглядається як еволюція в популяції програм. Якщо система знаходить програму, яка точно відтворює шукану залежність, вона починає вносити до неї невеликі модифікації і відбирає серед дочірніх програм лише ті, які підвищують точність.
Система "вирощує" кілька генетичних ліній програм, що конкурують між собою в точності знаходження шуканої залежності. Спеціальний транслюючий модуль перекладає знайдені залежності з внутрішньої мови системи на зрозумілу користувачеві мову (математичні формули, таблиці тощо), роблячи їх наочними. Для того, щоб зробити отримані результати більш зрозумілими, існує великий арсенал різноманітних засобів візуалізації виявлених залежностей.
Пошук залежності цільових змінних від інших факторів проводиться у формі функцій певного виду. Наприклад, в одному з найбільш вдалих алгоритмів цього типу - методі групового урахування аргументів (МГУА) залежність шукають у формі поліномів. Причому складні поліноми заміняються кількома простими, враховують лише деякі ознаки (групи аргументів). Отримані формули залежностей надаються до аналізу та інтерпретації.
Еволюційне програмування застосовне до різних інженерних завдань:
Системи управління, системи ідентифікації.
Маршрутизація трафіку.
Військове планування.
Обробка сигналів.
Ігрові та навчальні програми.
Основною перевагою еволюційних методів оптимізації є можливості вирішення завдань з великою розмірністю за рахунок поєднання елементів випадковості і строго визначених правил, основним з яких є закон еволюції: «перемагає найсильніший».
Іншим важливим чинником ефективності є відтворення процесів розвитку, де знайдені рішення за певним правилами породжують нові рішення, які будуть наслідувати кращі риси попередників. Як випадковий елемент використовується моделювання процесу мутації. З її допомогою характеристики певного рішення можуть бути випадково змінені, що надає новий напрямок в процесі еволюції і може пришвидшити процес вироблення кращого рішення.
Переваги еволюційних алгоритмів
Наочність схеми і базових принципів еволюційних обчислень.
Придатність для пошуку в складному просторі рішень великої розмірності.
Можливість підбору початкових умов, комбінування еволюційних обчислень, продовження процесу еволюції доки є необхідні ресурси.
Відсутність обмежень на вид цільової функції.
Широка область застосування.
Недоліки еволюційних алгоритмів
Еволюційні обчислення не гарантують оптимальності отриманого рішення, але за заданий час можна отримати кілька хороших альтернативних рішень.
Вимагається висока обчислювальна потужність.
Відносно невисока ефективність на завершальних фазах еволюційного процесу.
5.6. Алгоритми колективної поведінки мурашиної колонії
Мурашиний алгоритм — один з ефективних алгоритмів для знаходження наближених розв'язків задачі комівояжера, а також аналогічних завдань пошуку маршрутів на графах. Суть підходу полягає в аналізі та використанні моделі поведінки мурах, що шукають найкоротші шляхи від колонії до їжі.
Окрема мураха влаштована вкрай примітивно: всі її дії зводяться до елементарних реакцій на навколишнє оточення і своїх побратимів. Мураха не здатна аналізувати, робити висновки і шукати рішення. Ці факти, однак, не узгоджуються з успішністю мурах як виду. Вони існують на планеті понад 100 млн років, будують величезні житла та забезпечують себе всім необхідним.
Домогтися таких успіхів мурахі здатні завдяки своїй соціальності. Вони живуть лише в колективах – колоніях і повинні строго взаємодіяти за певними правилами, і тоді колонія цілком буде ефективною.
Колонія є повністю самоорганізованою і не має домінуючих особин, які роздають вказівки і координують дії. Кожна з мурах володіє інформацією тільки про локальну обстановку і не має уявлення про всю ситуації в цілому - тільки про те, що дізналася сама або явно чи неявно від своїх родичів. На неявних взаємодіях мурах засновано механізми пошуку найкоротшого шляху від мурашника до джерела їжі (рис.5.7).
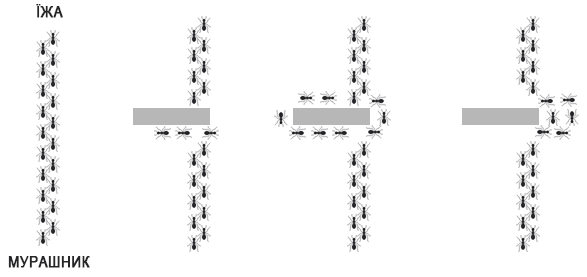
Рис.5.7. Наочний приклад поведінки мурах при доланні перешкод
На рисунку показано випадок, коли на шляху пересування мурах до їжі виникає перешкода. У цьому випадку потрібно прокласти новий оптимальний шлях. Після того, як мурахі дійшли до перешкоди, вони з рівною ймовірністю будуть її обходити як зліва так й справа. Кожен раз, проходячи від мурашника до джерела їжі і назад, мурахі залишають за собою доріжку феромонів.
Інші мурахі, відчувши такі сліди на землі, будуть інстинктивно скеровуватися до джерела їжі. Мурахі, які обрали коротший шлях, будуть його проходити швидше (туди/назад), і за кілька проходжень шлях буде більш насичений феромоном. Чим більше мурах проходить за певним шляхом і залишає феромон, тим привабливішим він стає для їх родичів. Але феромон має властивість й випаровуватися, тобто на довшій ділянці, по який пройде менша кількість мурах концентрація феромону буде значно меншою.
Така поведінка в мурашиній колонії має корисні властивості, що можна використати для моделювання
Випадковість. Для пошуку їжі мурахі орієнтуються на різні варіанти побудови свого шляху і на першому етапі напрямок руху обирають випадковим чином. Навіть, коли щільність феромону допомагає вибрати оптимальний (найкоротший) маршрут, залишаються "недовірливі особи", які не залишають спроби знайти більш оптимальні маршрути.
Багаторазовість. Безумовно, з одною або кількома мурахами навряд чи вийде здійснити вибір оптимального шляху. Потрібно багато спроб знайти найкоротший шлях або хоча б попередити інших, що не потрібно рухатися в цьому напрямку. В якості такого попередження виступає феромон і позитивний зворотний зв'язок.
Позитивний зворотний зв'язок. У зоологів це називається стигмерією (stigmergy). Стигмерія - це механізм непрямої координації, через навколишнє середовище між агентами чи діями, коли один суб'єкт взаємодії змінює деяку частину навколишнього середовища, а інші використовують інформацію про цей стан пізніше, коли знаходяться в околі даної частини. Таким чином, позитивний зворотний зв'язок це певна "колективна пам'ять" на основі феромону. Використовуючи цю "пам'ять" (на основі спроб і помилок) можна знайти правильне рішення.
Негативний зворотний зв'язок. Згодом феромон випаровується, що дозволяє мурахам адаптувати свою поведінку під зміни зовнішнього середовища. Розподіл феромону по простору пересування мурах є динамічною змінною глобальної пам'яті мурашника. Будь-яка мураха в фіксований момент часу може сприймати і змінювати лише одну локальну комірку цієї глобальної пам'яті.
Цільова функція. Найважливішим елементом алгоритму є цільова функція (фітнес-функція), яку потрібно оптимізувати (для мурашки це короткий маршрут). Але можна з успіхом вирішувати і інші подібні завдання (складання розкладу тощо) Кінцевою метою алгоритму є оптимізація (пошук глобального або прийнятного максимуму чи мінімуму). Алгоритм є евристичним, тобто не гарантує точного рішення, а тільки наближене або прийнятне.
Класичний мурашиний алгоритм
Мурашиний алгоритм моделює систему з простими агентами, яким для виконання дій потрібно невелику кількість пам'яті та нескладні обчислення. В основі алгоритму лежить поведінка мурашиної колонії — маркування доріжок певною кількістю феромону, який може з часом або накопичуватися або випаровуватися.
Н
 аочним поясненням мурашиного алгоритму є завдання пошуку найкоротшого шляху у задачі комівояжера.
аочним поясненням мурашиного алгоритму є завдання пошуку найкоротшого шляху у задачі комівояжера. Робота починається з розміщення мурашок у вершинах графа, потім починається рух мурашок, що мають пройти всі вершини в різний спосіб. Кожна мураха зберігає в пам'яті список пройдених їм вузлів (список заборон). Вибираючи вузол для наступного кроку, мураха «пам'ятає» про вже пройдені вузли і не розглядає їх як можливі для переходу. На кожному кроці список заборон поповнюється новим вузлом.
Крім списку заборон при виборі вузла для переходу мураха керується «привабливістю» ребер, які вона може пройти. Привабливість залежить, по-перше, від відстані між вузлами (вага ребра), а по-друге, від слідів феромонів, які залишили мурахі, що пройшли раніше. Природно, що на відміну від ваг ребер, які є константними, сліди феромонів оновлюються на кожній ітерації алгоритму: як і в природі, з часом сліди випаровуються, а мурахі, що проходять цим шляхом, навпаки, посилюють їх.
Перед новою ітерацією алгоритму, тобто перед тим, як мураха знову проходить вершини, список заборон очищується і мураха може знов обрати попередній шлях, ґрунтуючись на його привабливістю. Результати однієї ітерації звісно не нададуть хорошого рішення, проте, повторення алгоритму може видавати досить точний результат.
Переваги. Ефективний для TSP (Traveling Salesman Problem) з невеликою кількістю вузлів. Використовується в додатках, які можуть адаптуватися до змін. Завдяки пам'яті всієї колонії і випадковому вибору шляху не схильний до невдалих початкових рішень.
Застосування. Розрахунки комп'ютерних і телекомунікаційних мереж. Завдання комівояжера. Завдання розфарбування графа. Завдання оптимізації мережних трафіків.
Висновки
Значну роль в розвитку природних систем відіграє еволюція, тому дослідники прагнуть розробляти моделі, що реально пояснюють принципи роботи цього механізму: відтворення структури популяції, народження і виродження особин, колективна поведінка та події між ними.
Генетичні алгоритми є алгоритмами пошуку, що побудовані на принципах, подібних до принципів природного відбору і генетики. Насамперед, це принцип виживання найбільш перспективних рішень, обмін інформацією, в якій наявний елемент випадковості. Разом ці принципи спроможні моделювати природні процеси успадкування і мутації. Додатковою властивістю цих алгоритмів є невтручання людини в ітераційний процес пошуку, впливати можна лише опосередковано, задаючи певні параметри. Зберігається біологічна термінологія в спрощеному вигляді і основні поняття лінійної алгебри
Досягнення оптимуму в багатокритеріальних задачах є вкрай складним та вимагає значної кількості ресурсів. Генетичні алгоритми скеровані на знаходження кращого задовільного значення, а не оптимального рішення задачі. І така властивість сприяє розвитку і зростанню популярності генетичних алгоритмів.
Основу мурашиних алгоритмів оптимізації складає імітація самоорганізації мурашиної колонії. Колонія мурах може розглядатися як багатоагентна система, в якій кожен агент (мураха) функціонує автономно за дуже простими правилами. Але не зважаючи на примітивну поведінку агентів, поведінка всієї системи є розумною та ефективною.
Мурашині алгоритми використовують для складних комбінаторних задач, таких як задача комівояжера, маршрутизація, оптимізація, календарне планування тощо. Особливо ефективними мурашині алгоритми є при динамічній оптимізації процесів в розподілених нестаціонарних системах, наприклад, трафіки у телекомунікаційних мережах.
Контрольні питання
Які базові принципи покладено в основу генетичних алгоритмів
Назвіть причини введення до генетичних обчислень механізму мутації.
Які критерії можна застосувати для припинення роботи генетичного алгоритму?
Назвіть поширені завдання, що вирішують за допомогою генетичних алгоритмів.
Яку дію виконує кросинговер?
Навіть певні модифікації генетичних алгоритмів, що сприяють отриманню кращих результатів.
Яке основні завдання ставляться перед мурахами в мурашиних алгоритмах?
Назвіть фактори, що сприяють мурахам вибрати найкраще рішення.
Які фактори поведінки в мурашиній колонії враховуються для моделювання?
Перелічіть прикладні завдання, в яких можна використати мурашиний алгоритм
Використані джерела
А.П. Карпенко Сучасні алгоритми пошукової оптимізації. Алгоритми, що надихаються природою - http://baumanpress.ru/books/474/474.pdf
Еволюційні алгоритми - https://ru.coursera.org/lecture/vvedenie-v-iskusstvennyi-intellekt/evoliutsionnyie-alghoritmy-ocaze
Генетичний алгоритм - https://uk.wikipedia.org/wiki/Генетичний_алгоритм
Генетичні алгоритми. Ключові поняття і методи реалізації - http://www.znannya.org/?view=ga_general
Муравьиные алгоритмы - https://habr.com/ru/post/105302/
Чураков М., Якушев А. Мурашині алгоритми - https://blog.bullgare.com/wp-content/uploads/2019/05/aca.pdf
Мурашиний алгоритм. Опис математичної моделі - http://smart-blog.net/post/2359
Генетичний алгоритм. Просто про складне https://habr.com/ru/post/128704/