

Міністерство освіти і науки України
Уманський державний педагогічний університет імені Павла Тичини
Факультет інженерно – педагогічної освіти
Кафедра професійної освіти та компютерних технологій
Рефрат на тему:
«Суперскалярні процесори»
Підготував студент 19 групи
Вільчинський Михайло Володимирович
Перевірив: заступник декана з наукової роботи,
кандидат педагогічних наук,доцент
Малишевський Олег Володимирович
Умань-2019
Зміст
1
Вступ 3
Історія 5
Принципи побудови суперскалярних процесорів 6
Підсистеми декодування, переупорядкування та диспетчеризації 17
Підсистема виконання 18
Висновок 18
Список використаної літератури 20
Вступ
Сучасні високопродуктивні обчислювальні системи затребувані в широкому діапазоні областей. Продуктивність мікропроцесорних систем (МС) щорічно зростає на 25-35%. Проектування обчислювальних систем і мереж сучасної архітектури - складна задача, яка включає в себе розробку, тестування і налагодження як апаратного, так і програмного забезпечення.
Одним з методів підвищення ефективності розробки на всіх етапах проектування є використання комплексу програм, що моделюють роботу мікропроцесора і МС в цілому, а також їх базових компонентів окремо. Значно скоротити час розробки можна за рахунок побудови моделей досліджуваних систем . Подібні моделі виконуються на інструментальної (хостовой) машині і з певною точністю відтворюють поведінку цільової (моделюється) машини. Принцип роботи полягає в інтерпретації інструкцій цільової машини в моделируемом оточенні. Це дозволяє зіставляти альтернативи і обґрунтовано виробляти рішення, як при реалізації нових мікропроцесорних архітектур, так і при створенні обчислювальних засобів на основі стандартних архітектурних специфікацій.
В даний час так діють багато провідних компаній в області комп'ютерних технологій, хоча суттєві деталі їх методів залишаються закритими.
Сучасні мікропроцесори містять десять і більше обробних пристроїв, побудованих за конвеєрним принципом. Ефективна завантаження паралельно функціонуючих конвеєрів забезпечується або апаратурою процесора, або компілятором, який будує такий виконуваний модуль, який максимально завантажує все конвеєри. Процесори, що працюють за першим принципом, називаються суперскалярного, а по другому - з дуже довгим командним словом (VLIW).
Робота будь-якого конвеєра може бути припинена через конфлікти, які прийнято розділяти на три основні типи: за даними, з управління та структурні. оптимізуючий компілятор може побудувати код, в якому не буде конфліктів за даними та структурних. при цьому кількість одночасно виконуваних команд буде дорівнює числу конвеєрів, тобто можна, можливо вважати, що в процесорі виконується одна дуже довга команда. Саме такий підхід використовується у VLIW-процесорах. Вони мають дуже просту структуру і високу швидкодію. Недоліком таких процесорів є те, що виконуваний код програми залежить від структури пристрою (від числа конвеєрів). Для нової моделі процесора програму потрібно перекомпілювати. Розробники зазвичай не поставляють вихідний текст програми, що обмежує застосування VLIW-процесорів областю наукових досліджень.
У суперскалярні процесорах використовуються всі можливі способи усунення конфліктів.
Вони реалізуються динамічно. З ростом числа конвеєрів збільшується складність пристрою управління (УУ) ними, а також затримки в УУ. Вважається, що максимальна кількість конвеєрів дорівнює 10, а число ступенів в них - 20 [3]. Фірма AMD стверджує, що оптимальним є 10 ступенів (при більшій кількості збільшуються втрати через неправильне передбачення переходів).
Основною перевагою суперскалярні процесорів є незалежність виконуваного коду програми від їх структури і можливість його виконання на будь-якої моделі процесора. це гідність визначило переважне поширення суперскалярні процесорів.
Процесори з явним паралелізмом команд (EPIC - Explicitly Parallel Instruction Computing) поєднують в собі переваги обох архітектур. По суті, архітектура EPIC - це еволюція архітектури VLIW, яка абсорбувала в собі багато концепції суперскалярной.
EPIC має наступні відмінності від VLIW, які дозволяють усунути недоліки останньої: - Кожна група з декількох команд (інструкцій), звана бандлом (bundle), може мати стоповий біт, що позначає, що наступна група залежить від результатів роботи даної.
Інформація про залежності обчислюється компілятором, і тому апаратурі не доведеться проводити додаткову перевірку незалежності операндів.
- Для предподкачкі даних використовується команда програмної підкачки. ця операція збільшує ймовірність того, що до моменту виконання команди завантаження дані вже будуть в кеші.
- Інструкції перевірки завантаження забезпечують усунення конфліктів за даними.
Архітектура EPIC також включає в себе кілька концепцій для збільшення паралелізму команд: - Передбачення розг АЛПжень використовується для усунення конфліктів з управління.
- Відкладені виняткові ситуації, що використовують біт Not a thing в регістрах загального призначення, які дозволяють продовжувати спекулятивне виконання навіть після виняткових ситуацій.
- Вкрай великий регістровий файл, щоб уникнути необхідності в перейменування регістрів.
Історія
Першою в світі суперскалярною ЕОМ була CDC 6600 (1964 року), розроблена Сеймуром Креєм. В СРСР першою суперскалярною ЕОМ вважався комп'ютер» Ельбрус", розробка якого велася в 1973-1979 роках в ИТМиВТ . Основною структурною відмінністю Ельбрусу від CDC 6600 (крім зовсім іншої видимої програмісту системи команд — стекового типу) було те, що всі вузли в ньому були конвеєрізовані, як в сучасних суперскалярних мікропроцесорах. На підставі цього факту Б. А. Бабаян заявляв про пріоритет радянських ЕОМ в питанні побудови суперскалярних обчислювальних машин, проте вже наступна за CDC 6600 машина фірми Control Data, CDC 7600 (англ.), створена в 1969 році, за 4 роки до початку розробки «Ельбрусу», мала конвеєризацію виконавчих пристроїв. Крім того, дещо раніше (в 1967 році) фірмою IBM була випущена машина IBM 360/91, що використовує позачергове виконання, перейменування регістрів і конвеєризацію виконавчих пристроїв.
Першими промисловими суперскалярними однокристальними (англ. single-chip) мікропроцесорами стали мікропроцесор MC88100 1988 року фірми Motorola, мікропроцесор Intel i960CA 1989 року і мікропроцесор 29050 серії AMD 29000 1990 року. Першим же комерційно широкодоступним суперскалярним мікропроцесором став i960, що вийшов в 1988 році. У 1990-і роки основним виробником суперскалярних мікропроцесорів стала фірма Intel.
Всі процесори загального призначення, розроблені приблизно з 1998 року, крім процесорів, що використовуються в пристроях з низьким енергоспоживанням, у вбудованих системах і в пристроях, що живляться від батарейок, є суперскалярними.
Процесори Pentium з мікроархітектурою P5 (англ.) стали першими суперскалярними процесорами архітектури x86. Мікропроцесори Nx586, P6 Pentium Pro і AMD K5 стали першими суперскалярними процесорами, що перетворюють інструкції x86 у внутрішній код, який потім виконували.
Принципи побудови суперскалярних процесорів
1.1. Архітектура сучасних процесорів З моменту появи в 1971 р першого мікропроцесора Архітектура ЕОМ зазнала істотних змін. Скорочення технологічних норм дозволило розмістити на одному кристалі велике число виконавчих пристроїв: цілочисельних арифметико-логічних пристроїв, пристроїв виконання операцій над числами з плаваючою комою, пристроїв векторних обчислень Для їх ефективного використання потрібна була реалізація принципів конвеєризації обчислювального процесу і суперскалярної обробки.
Конвеєрна обробка являє собою процес, при якому складні дії поділяються на більш короткі стадії. Вони паралельне виконання дозволяє більш повно використовувати обробні ресурси конвеєра.
Стосовно до ЕОМ конвеєрна обробка знайшла широке поширення при виконанні процесорним пристроєм вхідного потоку команд. Так, цикл команди можна розділити на шість послідовних стадій: вибірку команди, декодування, обчислення адрес операндів, вибірку операндів, виконання команди і запис результатів. Процес обробки починається з вибірки чергової команди. Після отримання команди з підсистеми пам'яті процесор приступає до її декодування, тобто.
до перетворення коду операції в код одного або декількох послідовних керуючих дій, званих мікрокомандами. Якщо для виконання команди необхідно також отримати операнди з пам'яті, то одна з мікрокоманд управляє витяганням адрес операндів з команди і перетворенням їх в адреси фізичної пам'яті. При використанні віртуальної пам'яті обчислення адреси операнда може зайняти у мікропроцесора довгий час. Відразу ж після отримання всіх передбачених в команді операндів, мікропроцесор починає виконувати команду відповідно до керуючими сигналами, що задаються микрокомандой виконання. Отриманий таким чином результат може бути збережений в пам'яті або у внутрішньому регістрі за допомогою мікрокоманди записи результатів. Загальний час циклу виконання однієї команди прийнято називати латентністю.
Ідеалізована послідовність виконання команд на конвеєрі, що складається з шести стадій, показана на рис. 1, а.
Для більш повного використання апаратних ресурсів процесора і відповідно збільшення їх продуктивності використовуються конвеєри з великою кількістю стадій. Такі процесори називаються суперконвейерными. З рис. 1, Б випливає, що при поділі кожної стадії на два послідовних етапи може бути досягнута бічна продуктивність мікропроцесора.
Суперскалярна обробка ґрунтується на здатності процесора виконувати більше однієї простої (скалярної) операції за один такт, що досягається завдяки включенню до його складу декількох паралельно працюючих виконавчих пристроїв.
На рис. 1, в видно, що дублювання всіх блоків конвеєрного процесора дозволяє завершити обробку чотирьох команд на два такту швидше. Реалізація цього принципу спільно з впровадженням суперскалярної суперконвейерной обробки (рис. 1, г) дає
Рис. 1. Приклад виконання команд, що складаються зі стадій вибірки команди (ВК), декодування( ДК), обчислення адрес операндів( ВА), вибірки операндів (ВО), виконання команди(ІК), запису результатів (ЗР) з використанням конвеєрної структури (а), суперконвейерной структури (б), суперскалярної структури (в), суперскалярної суперконвейерной структури (г)
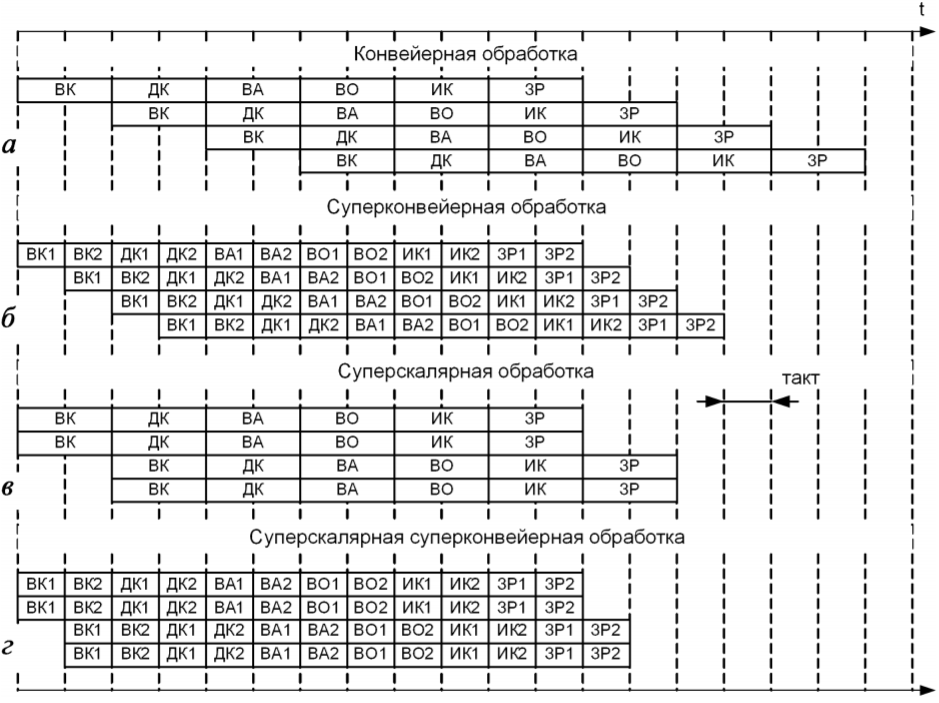
найкращий результат. У сучасних мікропроцесорах суперскалярність може забезпечуватися двома способами: виключно апаратним способом завдяки виявленню в потоці команд паралельних гілок; програмно-апаратним способом завдяки застосуванню спеціальних оптимізуючих компіляторів для завантаження паралельно працюючих пристроїв.
Впровадження суперскалярності і суперконвейерності стало істотним досягненням розробників ЕОМ. Першою успішно реалізованої ЕОМ, побудованої за вказаними принципами, є ЕОМ "Ельбрус-1", створена в 1978 р в Ітмівт ім. С. А. Лебедєва. Архітектурні рішення, закладені в цю ЕОМ, використовуються в сучасних мікропроцесорах. Широке поширення суперскалярні Процесори отримали в 1990-і роки, коли фірма IBM випустила комерційно успішний процесор RS / 6000 (1990 р.), а фірма Intel випустила мікропроцесор Pentium (1993 р.) і більш досконалі процесори сімейства P6 (Pentium Pro, Pentium II, Pentium III в 1995-1999 рр.
Однак крім явних переваг застосування конвеєра і дублювання його блоків в мікропроцесорах породжують ряд проблем, найбільш значуща з яких обумовлена наявністю команд переходу, що порушують природний порядок обчислень.
Частка таких команд в програмах істотна (приблизно 10 %), що призводить до збою ритмічної роботи конвеєра. Найбільший затримку в роботі конвеєра викликають команди умовних переходів, так як тільки після повного їх виконання стає можливим визначити адресу наступної виконуваної команди.
У сучасних мікропроцесорах для скорочення втрат часу при обробці таких команд широке застосування знайшли передбачення переходу і виконання альтернативних гілок програми.
Помітне збільшення тактової частоти мікропроцесорів і вдосконалення архітектури призвели до необхідності прискорення обміну інформацією між процесором і оперативною пам'яттю.
Досягнення цієї мети ускладнюється в зв'язку з тим, що швидкодія оперативної пам'яті зростає набагато повільніше, ніж продуктивність самих процесорів (розрив в продуктивності подвоюється щорічно [1]). Зростаюча потреба в розмірах оперативної пам'яті призводить до її поділу на блоки меншого розміру і робить скрутним інтенсивну обробку інформації на кордоні блоків. Для вирішення зазначених проблем використовується цілий комплекс архітектурних рішень.
* Спекулятивна вибірка даних і передбачення напрямки розгалуження. Обидва ці способи полягають в завчасному визначенні та отриманні з оперативної пам'яті тих команд і даних, які належить обробити процесору. Спекулятивний вибірка, ініційована самим процесором на основі аналізу потоку команд, що надходить, називається апаратною передвиборкою.
* Використання команд управління рівнями пам'яті: команди примусового завантаження даних в кеш-пам'ять і буфери читання / запису дозволяють оптимізувати процес обчислення для конкретного мікропроцесора. Спекулятивна вибірка, ініційована спеціальними командами, називається програмною передвиборкою.
* Невпорядковане виконання команд в процесорі. Цей принцип заснований на механізмі виявлення залежностей за даними.
За допомогою такої інформації процесор може змінити вихідний порядок виконання команд і мікрокоманд, закладений в програму.
* Апаратна реалізація непрямої адресації, що прискорює обчислення адрес операндів.
* Віртуалізація адресного простору, що реалізується у вигляді сегментно-сторінкової і більш складних типів організації пам'яті. Ці принципи передбачають визначення фізичної адреси оперативної пам'яті з логічної адреси, зазначеної в команді, за спеціальними таблицями. Для прискорення доступу до них застосовують спеціальну кеш-пам'ять (Translation Look-Aside Buffer-TLB), в яку поміщають часто використовувані рядки таблиць або результати перетворень.
* Використання пакетної передачі інформації. Такий спосіб застосовується в припущенні, що інформація вибирається з послідовних осередків ОП, і називається припущенням про купчастості адрес. Це дозволяє прискорити виконання багатьох додатків.
* Використання ієрархії пам'яті. Це рішення передбачає переміщення даних між швидкісним процесором і повільною пам'яттю через буферну і кеш-пам'ять. Кеш-пам'ять набагато менше за обсягом, ніж Оперативна, і містить часто використовувану процесором інформацію. Буфери покликані групувати дані в пакети, сприяючи прискоренню їх передачі по шинах.
* Примусове розділення потоків команд і даних. Отакий спосіб дозволяє оптимізувати обробку різнорідної інформації, що витягується з ОП.
Узагальнена структура процесора, що використовує перераховані архітектурні особливості та основні інформаційні потоки, показана на рис. 2. У процесорі реалізовані кілька
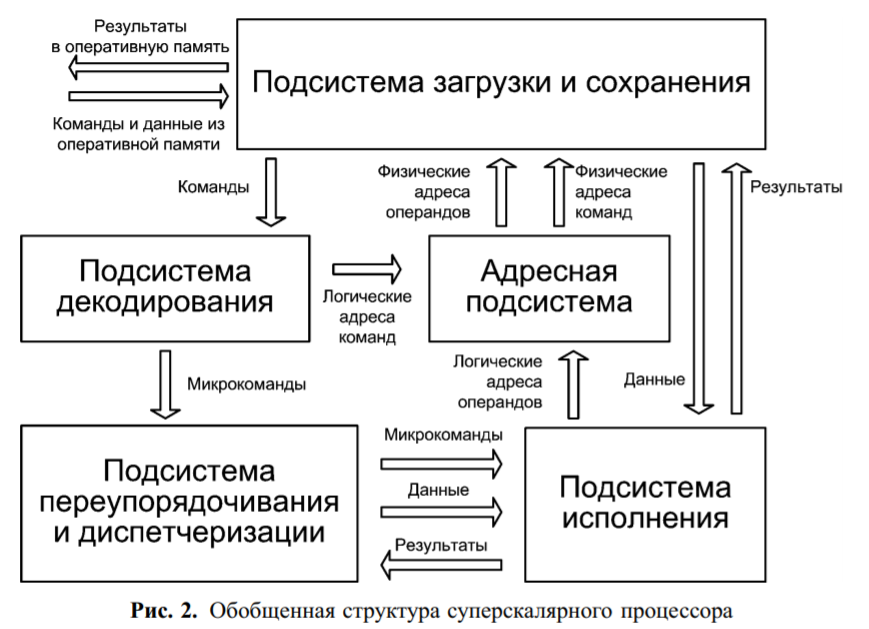 функціонально різних підсистем, що забезпечують конвеєрну і суперскалярну обробку інструкцій програми.
функціонально різних підсистем, що забезпечують конвеєрну і суперскалярну обробку інструкцій програми.Підсистема завантаження і збереження команд і даних забезпечує зв'язок процесора з ОП, а також виконує тимчасове зберігання і видачу іншим підсистемам кодів виконуваних команд, операндів і результатів. Ця підсистема отримує на вхід фізичні адреси команд і даних, після чого забезпечує вибірку затребуваної інформації з пам'яті і передає її в інші підсистеми.
Як правило, ця підсистема складається з пристрою шинного інтерфейсу, пристрою переупорядкування запитів до пам'яті і багаторівневої кеш-пам'яті для зберігання команд і даних. У деяких моделях мікропроцесорів в таку підсистему входить контролер пам'ять. Більш докладний опис логіки функціонування цієї та інших підсистем представлено в наступних підрозділах.
Адресна підсистема дозволяє мікропроцесору своєчасно визначати адреси затребуваних в обчислювальному процесі команд і даних, а також забезпечує перетворення логічних адрес в фізичні і видає запит на завантаження операндів у підсистему завантаження і збереження і вивантаження їх з неї. Цей підсистема, як правило, складається з пристрою обчислення адреси наступної команди, буферів швидкого сторінкового перетворення (TLB-буферів), блоку передбачення напрямку розгалуження.
Підсистема декодування призначена для визначення послідовності мікрокоманд, необхідних для реалізації надходить послідовності інструкцій програми. Звичайне вона складається з пам'яті мікропрограм, пристрою перекодування і декодування, блоку перейменування регістрів.
Підсистема переупорядкування і диспетчеризації реалізує функції зберігання декодованих мікрокоманд в очікуванні надходження їх операндів, розподіляє мікрокоманди в міру їх готовності на вільні виконавчі пристрої, зберігає результати обробки мікрокоманд і забезпечує своєчасне видалення виконаних мікрокоманд. Послідовність виконання мікрокоманд може відрізнятися від вихідної послідовності інструкцій програми. Дана підсистема складається з таблиці реєстрових псевдонімів, буфера переупорядкування мікрокоманд, пристрої видалення і відновлення, регістрів заміщення і архітектурних регістрів, буфера готових мікрокоманд, портів запуску.
Підсистема виконання складається з пристроїв, що безпосередньо обробляють операнди відповідно до кодів мікрокоманд. Крім арифметичних пристроїв, що обробляють числа з фіксованою і плаваючою комою, до таких пристроїв відносяться блоки, що обробляють мікрокоманди завантаження і вивантаження операндів (блок зв'язку з пам'яттю), і пристрій перевірки правильності передбачених переходів (пристрій арифметики перехід).
Розробники суперскалярних процесорів шукають ефективні шляхи подальшого підвищення їх продуктивності. Характеристики і структура таких процесорів і їх підсистем різні. У наступних підрозділах буде розглянута Архітектура суперскалярних процесорів на прикладі класичного сімейства P6, що еволюціонував в більш сучасні архітектури (Core, Pentium M). Короткий опис архітектури других семейств суперскалярных процессоров (NetBurst, MIPS, Sun SPARC Ultra III, POWER4) приведено в розд. 2
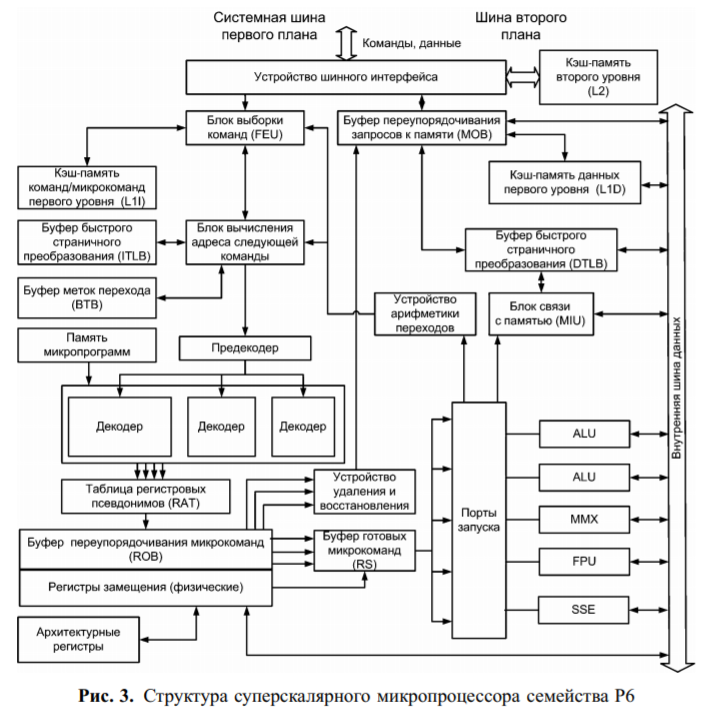
Підсистема завантаження та збереження
Підсистема завантаження і збереження процесорів сімейства P6 складається з пристрою шинного інтерфейсу, кеш-пам'яті другого рівня, кеш-пам'яті команд першого рівня, кеш-пам'яті даних першого рівня, блоку вибірки команд і Блоку переупорядкування запитів до пам'яті.
Пристрій шинного інтерфейсу (Bus Interface Unit, BIU) забезпечує взаємодію процесора з системною шиною, що є основним трактом передачі інформації в сучасних ЕОМ. По цій шині процесор може обмінюватися інформацією з іншими процесорами, звертатися до оперативної і кеш-пам'яті, а також до периферійних пристроїв.
Статус центрального тракту передачі даних накладає жорсткі вимоги на пропускну здатність системної шини. З метою її розвантаження в сучасних ЕОМ використовують ієрархію шин.
Так, периферійні пристрої підключають не безпосередньо до системної магістралі, а до шин введення/виведення, більш пристосованим до підключаються типів пристроїв (PCI, AGP і т.п.). Контролер таких шин реалізують в наборі мікросхем-чіпсеті (chipset), що випускається спільно з процесором. На рис. 4 показаний можливий варіант підключення периферійних шин через спеціальну мікросхему (концентратор) до системної шини. Окреме місце в цій ієрархії займає шина "другого плану" (Back Side Bus-BSB), Адресна підсистема У функції підсистеми обчислення адрес процесорів P6 входять: • забезпечення віртуалізації адресного простору, що реалізовується буферами швидкого сторінкового перетворення, блоком зв'язку з пам'яттю і блоком обчислення адреси наступної команди; • передбачення напрямки розгалуження, що реалізовується буфером міток переходу і блоком обчислення адреси наступної команди.
Розглянемо призначення цих пристроїв більш докладно.
Блок обчислення адреси наступної команди (Prediction Unit - PU) служить для визначення адреси чергової команди і видачі його в блок FIU. Як уже зазначалося, конвеєрна обробка передбачає безперервне надходження команд, виконання яких відбувається лише після декодування і підготовки операндов.
Очевидно, що очікування виконання команд розгалуження суттєво уповільнило б обробку, тому в процесорах активно застосовуються методи передбачення напрямки розгалуження.
Прискорене в порівнянні з іншими командами декодування команд переходу забезпечується завдяки попередньому скануванню блоку, ліченого з кеш-пам'яті команд L1I блоку. Зазначене дію дозволяє мінімізувати втрати часу. далі при виявленні команди безумовного переходу (команди виклику підпрограм, повернення з процедур і переривань, прямих переходів і т. п.) швидко обчислюється логічний адресу черговий команди.
Більш суттєві затримки в роботі конвеєра викликають команди умовного переходу, що пов'язано з неможливістю обчислення умови переходу до закінчення виконання всіх попередніх команд. Часткове вирішення цієї проблеми досягається застосуванням різних способів передбачення. Перший з них - статичне визначення напрямку розгалуження- заснований на аналізі попередньо зібраних відомостей. Така інформація впроваджується в програмний код на етапі компіляції і може бути отримана, наприклад, на основі завчасно виявленої нерівномірності результатів умовних переходів програми. Однак навіть при використанні великої кількості статистичних відомостей ефективність такого способу істотно нижче, ніж у динамічного передбачення.
Динамічне передбачення засноване на використанні передісторії переходів, що містить інформацію про результати виконання команд умовного переходу, що надходили в процесор раніше. Крім того, застосовуються відомі статистичні відомості. Наприклад, перехід у бік убування адрес (перехід назад) доцільно передбачати " досконалим», в той час як перехід у бік збільшення адрес (перехід вперед), навпаки, доцільно не передбачати. Це, зокрема, дещо прискорює обробку циклів з постумовою порівняно з циклами з передумовою.
Крім того, в залежності від складності реалізації алгоритми динамічного передбачення дозволяють виявити в програмі шаблонні кодові конструкції: цикли, поперемінні переходи, статистична інформація накопичується в спеціальній асоціативної пам'яті-буфері міток переходу (Branch Target Buffer-BTB), звернення до якої виконується за цільовою програмною адресою.
Підсистеми декодування, переупорядкування та диспетчеризації
Підсистема декодування служити для визначення послідовності мікрокоманд, необхідних для реалізації надходить послідовності інструкцій програми, і складається з предекодеров і декодерів інструкцій, а також пам'яті мікропрограм і Блоку перейменування регістрів.
Команди з кеш-пам'яті команд першого рівня L1I крім блоку обчислення адреси наступної команди надходять в блок декодування, де виконується передосвіта кожної надійшла інструкції в послідовність мікрокоманд. Мікрокоманда, відповідні однієї інструкції, називаються мікропрограмою і зберігаються в пам'яті мікропрограм. У сучасних мікропроцесорах для генерації мікропрограм використовується кілька декодерів, здатних паралельно видавати на наступні стадії конвеєра цілі групи мікрооперацій. Так, в процесорах P6 реалізовано три декодери, перший з яких може обробити будь-яку інструкцію і здоровий генерувати до чотирьох мікрокоманд за один такт, в той час як два інших дозволяють дешифрувати тільки прості інструкції, кожна з яких перетворюється в одну мікрокоманду. Таким чином, максимальна продуктивність декодерів в процесорах P6 досягається при компонуванні програмного коду в блоки по 16 байт, в яких на першому місці розміщується складна інструкція, а за нею слідують дві прості інструкція. Інше розміщення команд сповільнить процес декодування.
Складний формат команд, характерний для CISC-процесорів, призводить до істотного ускладнення декодерів. Наприклад, для набору команд процесорів x86 характерне застосування префіксів команд, що змінюють розмірність операндів і адрес, що вказують на необхідність повторення команд або змінюють сегмент за замовчуванням. Наявність префікса в інструкції істотно уповільнює декодування. Для усунення проблеми, пов'язаної з відмінністю довжини команд (від 1 до 15 байт), потрібно застосовувати додаткові складні пристрої розмітки інструкцій, що забезпечують прискорений пошук кодів операцій і визначення їх довжини.
Підсистема виконання
Підсистема виконання складається з пристроїв наступних типів:
* цілочисельних арифметико-логічних пристроїв;
* пристроїв адресної арифметики;
* пристроїв обробки чисел з плаваючою комою;
* пристроїв виконання цілочисельних MMX-операцій;
* пристроїв векторних обчислень над числами з плаваючоюкомою.
Цілочисельні арифметико-логічні пристрої (АЛП).
Процесор P6 містить два цілочисельних АЛП, що дозволяє виконувати дві операції за один такт роботи процесора. При цьому операція зсуву може бути виконана тільки на одному з АЛП, тобто латентність зсуву становить один такт при продуктивності, рівній одній операції за один такт. Латентність операцій додавання і віднімання становить один такт при продуктивності, що дорівнює двом операціям за один такт, що тим не менш часто виявляється недостатнім .
Для прискорення виконання арифметичних операцій з 32- і 64-розрядними операндами в наступних моделях процесорів Intel використовується конвеєризація АЛП спільно зі збільшенням тактової частоти роботи ступенів. Для цього застосовується поділ на стадії, в кожній з яких використовуються АЛП з меншою розрядністю .
Висновок
Суперскалярна обробка ґрунтується на здатності процесора виконувати більше однієї простої операції за один такт, що досягається завдяки дублюванню виконавчих пристроїв. Суперскалярний процесор може самостійно виконувати декілька інструкцій за один раз протягом одного такта. Він включає надлишкові ресурси виконання, наприклад, кілька плаваючих точок одиниць, arithmetic logic вузлів і цілочисельні шрифти. Цей тип процесора призначений для паралельних обчислень і виконання завдань без спеціального програмного забезпечення. Це може підвищити швидкість виконання багатьох ресурсномістких додатків шляхом маніпулювання і змінюючи коду. Суперскалярний процесор часто використовується в декількох класах комп`ютерів, в тому числі серверах, настільних комп`ютерах і навіть ноутбуках. Хоча деякі аспекти архітектури використовувалися в процесорах, починаючи з 1960-х років, правда про суперскалярні процесорах не було звільнено значно пізніше. Деякі Reduced Instruction Set Computing (RISC) процесори, продані в кінці 1980-х і початку 1990-х років були суперскалярного процесорами. Їхні прості ядра і фіксована довжина вказівок, диспетчеризація і планування паралельних інструкцій, виконувалися щодо легко. Багато НЕ RISC-процесорів, виготовлені з кінця 1990-х років, мали суперскалярну архітектуру. Суперскалярний процесор вбудований з низьким енергоспоживанням, працює і в поєднанні з іншими спеціалізованими процесорами часто як виняток, інші аспекти оптимізації їх конструкції замість паралельного виконання. Деякі процесори можуть спільно використовувати один канал з інструкціями для декількох потоків виконання, відомий як super-threading. Якщо функціональний блок знаходиться в режимі очікування, тому що він знаходиться в стані очікування по теперішній час потоку виконання, він може одночасно виконувати інструкції з іншого потоку. ця методика допомагає в повній мірі використовувати суперскалярний процесор , але не так ефективно, як одночасна багатопоточність (SMT). Один суперскалярний процесор може за допомогою SMT виконувати декілька інструкцій з декількох потоків одночасно. Одночасно виконуються потоки можуть конкурувати з системою і ресурсами процесора, що може значно сповільнити роботу системи. Процесори з багатоступінчатими потоками можуть одночасно виконувати декілька інструкцій, коли вони знаходяться на різних стадіях виконання. На відміну від цього, ряд інструкцій може виконуватися на тій же стадії, одночасно суперскалярним процесором. Хоча є велика схожість між цим типом процесорів і багатоядерними процесорами, але вони не ідентичні. Багатоядерний процесор в одному пристрої містить кілька процесорів, які називаються ядра.
Список використаної літератури
Бессонов О. Обзор микроархитектур современных десктопных процессоров. Июль 2006. — http://www.ixbt.com.
Э.Таненбаум. Архитектура компьютера = Structured Computer Organization. — 5-е изд. — СПб.: Питер, 2007. — С. 81—83. — 848 с. — (Классика Computer Science). — ISBN 5-469-01274-3. Архивная копия от 11 января 2012 на Wayback Machine
Г. И. Шпаковский. Организация параллельных ЭВМ и суперскалярных процессоров.
AMD64 Architectur: Programmer’s Manual. V. 1–3. Advanced Micro Devices, Sept. 2007. — http://www.amd.com.
Intel 64 and IA-32 Architecture: Optimization Reference Manual. Order Number 248966-016. Nov. 2007. — http://www.intel.com.
MIPS32 74Kc Processor Core Datasheet // MIPS Technologies, Inc. Dec. 14, 2007