
Міністерство освіти і науки
Національний університет «Львівська політехніка»
Інститут комп’ютерних наук та інформаційних технологій
Кафедра систем автоматизованого проектування

Контрольна робота №1
З дисципліни “Технології захисту інформації”
Тема: «Статистичний аналіз шифрованих та відкритих текстів»
Виконав:
студент КН-32з
Забава Ю.І.
Перевірив:
Іванців Р.Д.
Львів 2021
Зміст
Перелік скорочень
СЗІ - системи захисту інформації
ВТ - відкритий текст
ШТ - шифрований текст
ІВ - індекс відповідності
Вступ
Предметом вивчення в даній пояснювальній записці є криптографія (від грецького kryptós — прихований і gráphein — писати) — наука про методи захисту конфіденційності, цілісності і автентичності інформації. Аспектом вивчення у дисципліні є статистичний аналіз шифрованих та відкритих текстів
Метою вивчення є формування системних знань з принципів побудови криптографічного статистичного аналізу інформації, освоєння необхідних знань та отримання навиків для статистичного аналізу інформації в інформаційно-телекомунікаційних системах для розпізнавання шифрів.
В сучасних умовах дані які забезпечують життєво й історично важливі напрямки діяльності людини, перетворюється в цінний продукт і найважливіший крам, значущість якого мало-помалу наближається до вартості продуктів матеріального виробництва, що робить її (інформацію) об’єктом інтересів різного характеру (комерційного, соціального, кримінального та ін. Одним словом, зародження індустрії обробки інформації призвело до необхідності розвитку індустрії засобів захисту інформації.
Одним із аспектів захисту інформації є її статистичний аналіз, що допомагає якісно оцінити її статистичні характеристики для збільшення ефективності шифрування або знаходження ключа для дешифрування інформації у цілях, що не протирічать законодавству країни.
Короткі теоретичні відомості
Частотний аналіз, частотний криптоаналіз — метод криптоаналізу, який ґрунтується на частоті появи знаків шифротексту. Частотний аналіз передбачає, що частота появи заданої літери алфавіту в досить довгих текстах одна і та ж для різних текстів однієї мови. При цьому у випадку моноалфавітного шифрування якщо в шифротексті буде символ з аналогічною ймовірністю появи, то можна припустити, що він і є зазначеною зашифрованою буквою. Аналогічні міркування застосовуються до біграм (двобуквенні послідовностей), триграм і т.д. у разі поліалфавітного шифрів.
Метод частотного криптоаналізу відомий з IX-го століття (роботи Аль-Кінді), хоча найвідомішим випадком його застосування в реальному житті, можливо, є дешифровка єгипетських ієрогліфів Жаном-Франсуа Шампольйоном у 1822 році. У художній літературі найвідомішими згадками є оповідання «Золотий жук» Едгара По, «Танцюючі чоловічки» Конан Дойля, а також роман «Діти капітана Гранта» Жюль Верна. Починаючи з середини XX століття більшість використовуваних алгоритмів шифрування розробляються стійкими до частотного криптоаналізу, тому він застосовується, в основному, для навчання.
«Трактат про дешифрування криптографічних повідомлень» — книга, написана Абу Юсуфом Аль-Кінді, відома як перша згадка про частотний криптоаналіз. До середини IX століття найбільш поширеним у світі методом шифрування повідомлень моноалфавітний шифр (в якому кожній букві закодованого тексту ставиться у відповідність однозначно якась шифрована літера).
Арабські вчені прагнули отримувати знання попередніх цивілізацій, добуваючи єгипетські, вавилонські, індійські, китайські, перські, сирійські, вірменські, івритські, римські тексти і перекладаючи їх на арабську мову. Невідомо, хто перший винайшов частотний криптоаналіз, але перше відомий опис цього методу належить Аль-Кінді. Трактат про дешифрування криптографічних повідомлень Аль-Кінді дійшла до нас копією рукопису, яка була випадково знайдена в Бібліотеці Сулейманіє в Стамбулі. У вступі Аль-Кінді описує свій трактат як короткий і чіткий посібник, який допоможе читачеві швидко оволодіти основними прийомами криптоаналізу.
Аль-Кінді починає змістовну частину свого трактату з деяких міркувань математичної статистики. Він порівнює алфавіт з матеріалом з якого можна що-небудь виготовити, надавши йому потрібну форму. Наприклад, золото — матеріал, а зроблені з нього чашки, браслети та інші прикраси — різні форми цього матеріалу. Тому всі вироби зроблені з золота володіють схожими властивостями. Так само кожна мова володіє певними закономірностями, які можна використовувати при розшифровці повідомлень.
Наприклад, в алфавітах багатьох мов (в тому числі арабському) більше приголосних букв, ніж голосних. Однак якщо взяти який-небудь текст і порахувати частоту появи кожної букви в ньому, то найбільш частими літерами виявляється голосні) (в арабській мові найчастіша буква /( ,а:/), англійською, німецькою, французькою, іспанською – е, a російською — о).
Метод, запропонований Аль-Кінді легше пояснити з точки зору російського алфавіту. Насамперед, необхідно вивчити досить довгий уривок тексту російською мовою, або кілька уривків різних текстів, щоб встановити частоту появи кожної букви алфавіту. В російській мові о — найчастіша літера, після неї е, потім а і так далі, як вказано в таблиці. Потім вивчимо зашифрований текст і встановимо частоту появи кожного символу в ньому. Наприклад, якщо самий частий символ в зашифрованому тексті Ю, то, найімовірніше, його слід замінити на літеру о. Якщо другий по частоті символ зашифрованого тексту е, то його, ймовірно, слід замінити на є, і так далі. Завдяки методу Аль-Кінді, відомому як частотний криптоаналіз, не потрібно перевіряти кожен з мільярдів потенційних ключів. Замість цього можна розшифрувати повідомлення, просто проаналізувавши частоту символів в ньому. Тим не менш, частотний криптоаналіз не вирішує повністю завдання злому моноалфавітних шифрів. Його застосування залежить від величини й характеру тексту. Середні частоти літер будь-якої мови не завжди будуть відповідати частоті букв конкретного тексту. Наприклад, коротке повідомлення, в якому обговорюється вплив атмосфери на рух зебр в Африці «Через озонові дірки від Занзибара до Замбії і Заїру зебри бігають зигзагами», якщо буде зашифрованно моноалфавітні шифром, не вдасться дешифрувати з допомогою простого частотного криптоаналізу. Так як буква з в цьому повідомленні зустрічається на порядок частіше, ніж в простій мові. У технічних текстах рідкісна літера ф може стати досить частою у зв'язку з частим використанням таких слів, як функція, диференціал, дифузія, коефіцієнт і т. ін..Якщо не вдається розшифрувати криптограму з допомогою простого частотного криптоаналізу (наприклад, якщо повідомлення занадто коротке), Аль-Кінді пропонує використовувати характерні поєднання букв або, навпаки, непоєднуваність певних букв одна з одною. Наприклад, найбільш поширені біграми (групи з двох літер) російської мови: ст, але, ен, то, на, ів, ні, ра, у, до. Важлива статистика сполучуваності голосних і приголосних літер. Наприклад, перед буквами ь, ы, ъ та після е не можуть стояти голосні, а після голосної літери слідує приголосна з ймовірністю 87 %. Так само підказкою для криптоаналітика можуть бути загальноприйняті вступні слова, які використовуються майже в кожній мові.
Статистичний аналіз шифрованих та відкритих текстів
Залежність статистичних характеристик від обраної мови
Для кожної мови (українська, білоруська, англійська, ...) є характерні статистичні характеристики ВТ і ШТ. Мова йде про частоту використовування всіх букв алфавіту у ВТ і ШТ. Крім частотних характеристик використання окремих букв в криптоаналізі досліджуються частоти використання буквосполучень у ВТ і ШТ.
Необхідно відзначити, що реальні повідомлення для будь-якої конкретної мови, характеризуються певною надмірністю. Статистика частот зустрічання елементів повідомлень свідчить про їх нерівномірний розподіл.
Зокрема, для достатньо великого обсягу літературного тексту російською мовою буквами, що часто зустрічаються, виявляються {о, и}, серед букв англійської мови, що часто зустрічаються, – символи {e,t}.
Таблиця 1.1 - Відносні частоти зустрічання букв англійської мови (вибірка 300 000 букв газетно-журнального тексту)
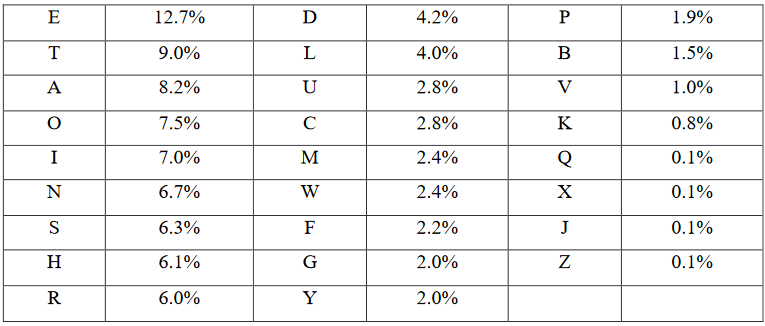
Крім цих параметрів необхідно виділити кількість символів, які використовуються в ШТ. Окремі символи можуть замінятися іншими окремими символами або цифровими замінниками. Значність цифрозамінників визначають з допомогою аналізу ШТ. Для цього використовується аналіз повторень однакових груп (буквосполучень) в ШТ і аналіз відстаней між ними. Цифрозамінники букв ВТ можуть замінятися 2-х, 3-х, 5-х значними цифровими групами. Якщо є бажання не збільшувати об’єм ШТ порівняно з ВТ, то частіше використовуються 2-х значні цифрові групи. Таким чином на першому етапі роботи з ШТ виконується відповідальна робота для визначення мови, яка відповідає ВТ, визначається можливі шифри, які використані для формування ШТ. Достовірність отриманих статистичних характеристик залежить перш за все від кількісних характеристик обробленого матеріалу. Якщо кількість символів ВТ і ШТ обчислюється кількома десятками, то такі статистичні дані не можуть мати високої достовірності. Статистичні дані можна сприймати як більш-менш достовірні, якщо кількість символів обчислюється кількома сотнями (і більше).
Індекс відповідності
Більшість повідомлень, зашифрованих методом перестановки або одно алфавітної підстановки, зберігають характерний частотний розподіл і, таким чином, дають крипто-аналітику шлях до розкриття шифру. Криптоаналитики часто використовують індекс відповідності (ІВ) для визначення того, чи знаходяться вони на правильному шляху.
По визначенню ІВ являє собою оцінку суми квадратів ймовірностей кожної букви. Це використовується особливо у тих випадках, коли об'єм зашифрованого тексту відносно великий. Шифровки, які дають значення ІВ більші, ніж 0,066 (для англійської мови), самі повідомляють про те, що ймовірно використовувалася одноалфавітна підстановка, даючи, таким чином криптоаналітикам інструмент для того, щоб приступити до розгадки шифру. Якщо ІВ знаходиться між 0,052 і 0,066, то, ймовірно, був використаний двохалфавітний шифр підстановки. Криптоаналітик просто бере символ, що найчастіше зустрічається, і передбачає, що це пропуск, потім бере наступний найбільш частий символ і передбачає, що це Е, і т.д., щоб прийти до можливого рішення. Цей процес можна автоматизувати застосувавши ЕОМ, однак аналіз можливих варіантів повідомлень повинна робити людина.
Справа дуже ускладнюється, коли криптоаналітик стикається з рівномірним розподілом символів (IВ = 1/26 = 0,038 для англійської мови), який виходить при використанні багатоалфавітної підстановки.
На наступних етапах виконуються певні дії для отримання ВТ на основі ШТ і статистичних даних, які отримані при статистичній обробці ШТ.
Математична модель дослідження текстів
Відзначені властивості мов використовуються криптоаналітиками при розкритті шифрів, тому для оцінки властивостей шифрованих текстів необхідно мати відповідну інформацію про ймовірнісні характеристики відкритих повідомлень.
З вказаною метою використовується ряд математичних моделей відкритих текстів. Наведемо приклади найпоширеніших моделей, що характеризують їх важливі ймовірнісно-статистичні властивості.
Відкритий текст є послідовністю поліноміальних випробувань на множині виходів з вектором зустрічності окремих знаків .
Це одна з найпоширеніших моделей відкритого тексту, яка дозволяє вирішувати задачі, пов'язані з класом так званих потокових шифрів.
Відзначимо, що відповідно до схеми незалежних випробувань використовується характеристика невизначеності або міра інформації, вибираної з експерименту.

Ентропією ймовірності схеми
 називається величина
називається величина 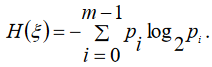
Згідно з теорією кодування, будь-який вихід імовірнісної схеми може бути закодований символами 0 і 1 так, що одержана довжина кодового слова буде скільки завгодно близька зверху до
Неважко показати, що функція ентропії опукла вгору і досягає свого максимуму
З ентропією пов'язана ще одна характеристика – надмірність мови,
яка обчислюється за формулою
 .
.Поняття надмірності мови виникло у зв'язку з тим, що максимальна інформація, яку міг би нести кожний символ повідомлення, в рівноймовірний схемі рівна
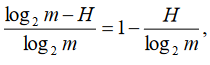
умовно кажучи, показує, яку частку символів повідомлення можна пропустити без істотної втрати значення. Зокрема, очевидно, що викреслювання з тексту, написаного російською мовою всіх голосних букв практично не знижує його інформативності. Більш того, в деяких мовах до 70-80 % знаків тексту можна видалити без істотної втрати значення.
Як наслідок, для m-буквеного алфавіту кількість смислових текстів (із заданими обмеженнями зустрічання букв) значно менша числа усіх можливих наборів з N букв, рівного Nm .
Згідно з теоремою Мак-Міллана число відкритих текстів для реальної мови з величиною ентропії на один знак тексту H для достатньо великих оцінюється величиною
Інша модель – відкритий текст
При цьому, принаймні, для деяких
нерівність:
Ще одна модель – відкритий текст
Дана модель дозволяє враховувати наявність залежностей між знаками відкритого тексту, а тому використовується для побудови критеріїв, за допомогою яких відбраковуются помилкові варіанти ключів. Статистичні властивості реальних відкритих текстів є початковими даними для проведення криптоаналітичних атак і оцінки практичної стійкості шифр систем.
Статистичний аналіз для одноалфавітних підстановок
Одним з важливих підкласів методів заміни є одноалфавітні (або моноалфавітні) підстановки, в яких встановлюється однозначна відповідність між кожним знаком ai вихідного алфавіту повідомлень A і відповідним знаком ei зашифрованого тексту E.
Одноалфавітна підстановка іноді називається також простою заміною, так як є найпростішим шифром заміни. Зашифроване повідомлення з використанням будь-якого шифру моноалфавітної підстановки виходить таким чином. Береться черговий знак з вихідного повідомлення. Визначається його позиція в стовпці таблиці замін. У зашифроване повідомлення вставляється шифрований символ з цього ж рядка таблиці замін. Отриманий таким чином текст має порівняно низький рівень захисту, так як вихідний і зашифрований тексти мають однакові статистичні закономірності. При цьому не має значення, які символи використані для заміни - примішані символи вихідного алфавіту чи таємничі знаки.
Зашифроване повідомлення може бути розкрите шляхом так званого частотного криптоаналізу. Для цього можуть бути використані деякі статистичні дані мови, якою написано повідомлення.
Відомо, що в текстах російською мовою найбільш часто зустрічаються символи О, І. Трохи рідше зустрічаються букви Е, А. З приголосних найчастіші символи Т, Н, Р, С. У розпорядженні криптоаналітиків є спеціальні таблиці частот зустрічальності символів для текстів різних типів - наукових, мистецьких і т.д.
Криптоаналітика уважно вивчає отриману криптограму, підраховуючи при цьому, які символи скільки разів зустрілися. Спочатку найбільш часто зустрічаються знаки зашифрованого повідомлення замінюються, наприклад, буквами О. Далі виробляється спроба визначити місця для букв І, Е, А. Потім підставляються найбільш часто зустрічаються приголосні. На кожному етапі оцінюється можливість "поєднання" тих чи інших букв. Наприклад, в російських словах важко знайти чотири поспіль голосні літери, слова в російській мові не починаються з літери И і т.д. Насправді для кожного природної мови (російської, англійської і т.д.) існує безліч закономірностей, які допомагають розкрити фахівцеві зашифровані противником повідомлення.
Залежність точності криптоаналізу від довжини повідомлення
Можливість однозначного криптоаналізу безпосередньо залежить від довжини перехопленого повідомлення. Подивимося, з чим це пов'язано. Нехай, наприклад, в руки криптоаналітиків потрапило зашифроване за допомогою деякого шифру одноалфавітної заміни повідомлення:
ТНФЖ.ИПЩЪРЪ
Це повідомлення складається з 11 символів. Нехай відомо, що ці символи складають ціле повідомлення, а не фрагмент більш великого тексту. У цьому випадку наше зашифроване повідомлення складається з одного або декількох цілих слів. У зашифрованому повідомленні символ Ъ зустрічається 2 рази. Припустимо, що у відкритому тексті на місці зашифрованого знака Ъ стоїть голосна О, А, І чи Є. Підставимо на місце Ъ ці букви і оцінимо можливість подальшого криптоанализу
Варіанти першого етапу криптоаналізу
Зашифроване повідомлення
Т Н Ф Ж . И П Щ Ъ Р Ъ
Після заміни Ъ на О О О
Після заміни Ъ на А А А
Після заміни Ъ на И И И
Після заміни Ъ на Е Е Е
Всі наведені варіанти заміни можуть зустрітися на практиці. Спробуємо підібрати якісь варіанти повідомлень, враховуючи, що в криптограмі інші символи зустрічаються по одному разу (таблиця 2.2).
Варіанти другого етапу криптоаналізу
Зашифроване повідомлення
Т Н Ф Ж . И П Щ Ъ Р Ъ
Варіанти дешифрованих повідомлень
Ж Д И С У М Р А К А
Д Ж О Н А У Б И Л И
В С Е Х П О Б И Л И
М Ы П О Б Е Д И Л И
Крім вищенаведених, можна підібрати ще велику кількість відповідних фраз. Таким чином, якщо нам нічого не відомо заздалегідь про зміст перехопленого повідомлення малої довжини, дешифрувати його однозначно не вийде.
Якщо ж у руки криптоаналітиків потрапляє досить довге повідомлення, зашифроване методом простої заміни, його зазвичай вдається успішно дешифрувати. На допомогу фахівцям з розкриття криптограм приходять статистичні закономірності мови. Чим довше зашифроване повідомлення, тим більша ймовірність його однозначного дешифрування.
Цікаво, що якщо спробувати замаскувати статистичні характеристики відкритого тексту, то завдання розшифрування шифру простої заміни значно ускладнилося. Наприклад, з цією метою можна перед шифруванням "стискати" відкритий текст з використанням комп'ютерних програм-архіваторів.
З ускладненням правил заміни збільшується надійність шифрування. Можна заміняти не окремі символи, а, наприклад, дволітерні поєднання - біграми. Оцінимо розмір такої таблиці замін. Якщо вихідний алфавіт містить N символів, то вектор змін для біграмного шифру повинен містити N2пар "відкр. текст - зашифрован. текст". Таблицю замін для такого шифру можна також записати і в іншому вигляді: заголовки стовпців відповідають першій букві біграми, а заголовки рядків - другій, причому елементи таблиці заповнені замінюють символами. В такій таблиці буде N рядків і N стовпців.
Можливі варіанти використання триграммного або взагалі n-граммного шифру. Такі шифри володіють вищою криптостійкістю, але вони складніші для реалізації і вимагають набагато більшої кількості ключової інформації (великий обсяг таблиці замін). В цілому, всі n-грамні шифри можуть бути розкриті за допомогою частотного криптоаналізу, тільки використовується статистика зустрічаємості не окремих символів, а сполучень з n символів.
Висновки
Частотний аналіз, частотний криптоаналіз — метод криптоаналізу, який ґрунтується на частоті появи знаків шифротексту. Частотний аналіз передбачає, що частота появи заданої літери алфавіту в досить довгих текстах одна і та ж для різних текстів однієї мови. При цьому у випадку моноалфавітного шифрування якщо в шифротексті буде символ з аналогічною ймовірністю появи, то можна припустити, що він і є зазначеною зашифрованою буквою. Аналогічні міркування застосовуються до біграм (двобуквенні послідовностей), триграм і т.д. у разі поліалфавітного шифрів.
Відзначені властивості мов використовуються криптоаналітиками при розкритті шифрів, тому для оцінки властивостей шифрованих текстів необхідно мати відповідну інформацію про ймовірнісні характеристики відкритих повідомлень.
Одним із аспектів захисту інформації є її статистичний аналіз, що допомагає якісно оцінити її статистичні характеристики для збільшення ефективності шифрування або знаходження ключа для дешифрування інформації у цілях, що не протирічать законодавству країни.
Більшість повідомлень, зашифрованих методом перестановки або одно алфавітної підстановки, зберігають характерний частотний розподіл і, таким чином, дають крипто-аналітику шлях до розкриття шифру. Криптоаналитики часто використовують індекс відповідності (ІВ) для визначення того, чи знаходяться вони на правильному шляху.
Можливість однозначного криптоаналізу безпосередньо залежить від довжини перехопленого повідомлення.
Список літератури
Венбо Мао. Современная криптография. Теория и практика. М: Вильямс, 2005. – 768 с.
Бернет С., Пэйн С., Криптография. Официальное руководство RSA Security. Изд. 2-е, стереотипное. – М.: ООО «Бином-Пресс», 2007. – 384 с.: ил.
Аграновский А.В., Хади Р.А. Практическая криптография: алгоритмы и их программирование. – М.: СОЛОН-Пресс, 2002. – 256 с.
Адаменко М.В. Основы классической криптологии: секреты шифров и кодов. – М.: ДМК Пресс, 2012. – 256 с.
Бабаш А. В. Криптография. – М.: СОЛОН-Пресс, 2007. – 511 с.
Баричев С. Г., Гончаров В. В., Серов Р. Е. Основы современной криптографии: Учебное пособие. М.: Горячая Линия - Телеком, 2002. – 175 с.
Ростовцев А.Г., Маховенко Е.Б. Теоретическая криптография. М.: Издательство: АНО НПО "Профессионал", 2005. – 480 с.
Алферов А.П., Зубов А.Ю., Кузьмин А.С., Черемушкин А.В. Основы криптографии. – М.: Гелиос АРВ, 2001. – 480 с.
Маховенко Е. Б. Теоретико-числовые методы в криптографии. М.: Гелиос АРВ, 2006.–320 с.
Мухачев В.А., Хорошко В.А. Методы практической криптографии. К.: ООО Полиграф-Консалтинг, 2005. – 209 с.
Рябко Б.Я., Фионов А.Н. Криптографические методы защиты информации. М.: Горячая линия – Телеком, 2005. – 229 с.
Ростовцев А.Г. Алгебраические основы криптографии. М.: НПО «Мир и семья», ООО «Интерлайн», 2000. – 256 с.