
Ім'я файлу: Розраха.docx
Розширення: docx
Розмір: 845кб.
Дата: 12.08.2021
скачати
Пов'язані файли:
5.docx
Лаба 4_РТП_СЗІ_Кліщ Богдан.docx
Лаба 5_РТП_СЗІ_Кліщ.docx
Тести, статистика праці.docx
Реферат Лесько П.В. Авторське право ЕЛЕП-11.docx.doc
Індивідуальна нормативне.docx
lab2.docx
ЦЕРКВА РІЗДВА ПРЕСВЯТОЇ БОГОРОДИЦІ У САМБОРІ.docx
ШАБЕЛЬКО КУРСОВА.docx
Сучасні методики здорового харчування.docx
Звіт до БД 2.docx
звіт_від_ред.docx
lab_8_Kravets.docx
Сєрий.docx
Сенсорне виховання.doc
СПЗ_ЛАБ_1.docx
lab5_бд.docx
Фізика5 Моя лаба.doc
Вебинар англ.docx
5.docx
ЛР 3 ФДП.docx
Методичка до ПЗ №5-6.doc
зразок РГР 2021 (1).docx
курсова 1.docx
Міністерство_освіти_та_науки_України_PI.docx
Контрольна робота Павло Коцаба.docx
Метод Баркера.docx
Grej_R._S.docx
знайомий реферат.docx
ОКРО.docx
Zvit№1ПСМ.doc
Розширення: docx
Розмір: 845кб.
Дата: 12.08.2021
скачати
Пов'язані файли:
5.docx
Лаба 4_РТП_СЗІ_Кліщ Богдан.docx
Лаба 5_РТП_СЗІ_Кліщ.docx
Тести, статистика праці.docx
Реферат Лесько П.В. Авторське право ЕЛЕП-11.docx.doc
Індивідуальна нормативне.docx
lab2.docx
ЦЕРКВА РІЗДВА ПРЕСВЯТОЇ БОГОРОДИЦІ У САМБОРІ.docx
ШАБЕЛЬКО КУРСОВА.docx
Сучасні методики здорового харчування.docx
Звіт до БД 2.docx
звіт_від_ред.docx
lab_8_Kravets.docx
Сєрий.docx
Сенсорне виховання.doc
СПЗ_ЛАБ_1.docx
lab5_бд.docx
Фізика5 Моя лаба.doc
Вебинар англ.docx
5.docx
ЛР 3 ФДП.docx
Методичка до ПЗ №5-6.doc
зразок РГР 2021 (1).docx
курсова 1.docx
Міністерство_освіти_та_науки_України_PI.docx
Контрольна робота Павло Коцаба.docx
Метод Баркера.docx
Grej_R._S.docx
знайомий реферат.docx
ОКРО.docx
Zvit№1ПСМ.doc
Міністерство освіти і науки, молоді та спорту України
Національний університет «Львівська політехніка»
Кафедра ЕОМ

Розрахункова робота
з дисципліни:
«Паралельні та розподілені обчислення»
на тему:
«Паралельне виконання операцій над матрицями та векторами»
Виконав:
Студент групи КІ-36
Чинков М.Д.
Прийняв:
Козак Н.Б.
Львів – 2021
Анотація
В даній розрахунковій роботі розроблено алгоритм паралельного перемноження матриць на структурі з восьми процесорів. Завантаження даних відбувається для всіх процесорів з одного елемента пам’яті. Вхідні матриці мають розмірності А(290*168) та В(168*349).
Робота складається з розрахунку часових характеристик алгоритму, розробки функціональної схеми алгоритму та програмної реалізації. Відповідно до часових затрат паралельного алгоритму визначено його ефективність відносно послідовного.
Програмно, алгоритм реалізований на С++ з простим інтуєтивним інтерфейсом, та з використанням MPI.
Зміст
Анотація 2
Зміст 3
1.Розрахунок варіанту 5
2.Теоретичний розділ 6
3.Розробка функціональної схеми 10
4.Розрахунковий розділ 11
Завантаження (Tz): 11
Обчислення: 12
Вивантаження (Tw): 13
Загальний час роботи (Т): 13
Умовний час виконання послідовного алгоритму 14
Час завантаження (Tz): 14
Час вивантаження (Tw): 14
Час операції пересилання (TP): 14
Час обчислення (Tus): 14
Загальний час роботи (Т): 14
5.Результат моделювання роботи 15
Висновки: 23
Додаток А (код до МРІ проекту) 24
Header.h: 24
file.cpp: 24
input.cpp: 26
main.cpp: 29
} 30
Operations.cpp: 30
P0.cpp: 30
P1.cpp: 32
P2.cpp: 34
P3.cpp: 36
P4.cpp: 39
P5.cpp: 41
P6.cpp: 43
P7.cpp: 45
types.cpp: 47
Додаток В (код до послідовного розв’язання) 47
Header.h: 47
file.cpp: 48
input.cpp: 49
main.cpp: 50
Operations.cpp: 50
P0.cpp: 51
types.cpp: 51
Розрахунок варіанту
Вхідні дані студента:
Чинков Михайло Денисович
КІ – 36
1809213 (номер залікової)
Розробити схему та описати процедуру перемноження матриці А (розмірністю N1*N2) на матрицю В (розмірністю N2*N3) на структурі з восьми процесорів. Для цієї структури визначити час виконання алгоритму, відсоток послідовної частини алгоритму та ефективність алгоритму.
N1 = 290, N2 = 168, N3 = 349 Отже маємо матрицю А(290*168) та матрицю В(168*349)
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| Ч | И | Н | К | О | В | М | И | Х | А | Й | Л | О | Д | Е | Н | И | С | О | В | И | Ч |
| 8 | 7 | 2 | 3 | | | 1 | | 6 | | 4 | | | | 5 | | | | | | | |
Отримаємо - МНКЙЕХИЧ
Таблиця 1. Кодування букв
| 7 | 3 | 4 | 11 | 15 | 9 | 2 | 1 |
| М | Н | К | Й | Е | Х | И | Ч |
| 43 | 134 | 47 | 146 | 171 | 127 | 91 | 49 |
| 0010 1011 | 1000 0110 | 0010 1111 | 1001 0010 | 1010 1011 | 0111 1111 | 0101 1011 | 0011 0001 |
Таблиця 2. Матриця суміжності
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
| 2 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 |
| 3 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 4 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 |
| 5 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| 6 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 |
| 7 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
Type = (
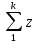 i)mod3 + 1=(1+8+9+2+1+3)mod3+1=24mod3 + 1 = 1
i)mod3 + 1=(1+8+9+2+1+3)mod3+1=24mod3 + 1 = 1z = 1809213 (номер залікової книжки)
Type = 1 спільна пам’ять.
tU = 10*tS = 3*tP = 2*tZ = 4*tW
Таблиця 3. Часові параметри
| Співвідношення часових параметрів | Пояснення |
| tu = 4*tw | час виконання однієї операції множення |
| ts = 4*tw/10 | час виконання однієї операції сумування |
| tp = 4*tw/3 | час виконання однієї операції пересилання даних між процесорами |
| tz = 2*tw | час виконання операції завантаження одних даних |
| tW | час виконання операції вивантаження одних даних |
Теоретичний розділ
Особливості використання технології паралельного програмування Message Passing Interface (MPI).
MPI - бібліотека функцій, яка забезпечує взаємодію паралельних процесів за допомогою механізму передачі повідомлень і не має ніяких засобів для розподілення процесів по обчислювальних вузлах і для запуску їх на виконання. МРІ не містить механізмів динамічного створення і знищення процесів під час виконання програми.
Для ідентифікації наборів процесів вводиться поняття групи і комунікатора.
Процеси об’єднуються в групи, можуть бути вкладені групи. Усередині групи всі процеси понумеровані. З кожною групою асоційований свій комунікатор. Тому при здійсненні пересилок необхідно вказати ідентифікатор групи, усередині якої проводиться це пересилка.
Процедури МРІ:
- ініціалізації та закриття МРІ –процесів;
- реалізації комутаційних операцій типу “точка-точка”;
- реалізації колективних операцій;
- для роботи з групами процесів і комунікаторами;
- для роботи з структурами даних;
- формування топології процесів.
До базових функцій МРІ відносяться:
ініціалізація МРІ;
завершення МРІ;
визначення кількості процесів в області зв’язку;
визначення номеру процесу, який виконується;
передача повідомлень;
приймання повідомлень;
функції відліку часу.
Кожна МРІ – функція характеризується способом виконання.
Локальна функція – виконується всередині процесу, що її викликав. Її завершення не вимагає комунікацій.
Нелокальна функція – для її завершення необхідно виконати МРІ – процедуру іншим процесом.
Глобальна функція – процедуру повинні виконати всі процеси групи. Невиконання цієї умови може привести до “зависання” задачі.
Блокуюча функція – повернення керування з процедури гарантує можливість повторного використання параметрів, які приймали участь у виклику. Ніякої змін в стан процесу, що викликав блокуючий запит до виходу з процедури не може відбуватися.
Неблокуюча функція – повернення з процедури відбувається негайно, без очікування завершення операції. Завершення неблокуючих операцій здійснюється спеціальними функціями.
Операції обміну повідомленнями
Розглянемо: режими обміну, обмін типу “точка-точка”, колективний обмін, способи реалізації моделі передачі повідомлень.
Режими обміну:
В загальному випадку є чотири режими обміну: асинхронний (стандартний), синхронний, з буферизацією, по “готовності”.
Обмін типу “точка-точка” – найпростіша форма обміну повідомленнями, в якій приймають участь тільки два процеси: джерело і адресат. Є кілька різновидностей двохточкового обміну:
синхронний обмін – супроводжується повідомленням про завершення прийому повідомлення;
асинхронний обмін – таким повідомленням не супроводжується;
блокуючі прийом/передача – призупиняють виконання процесу на час приймання повідомлення. Організація блокуючого обміну повідомленнями наведена на рис.2.7;
неблокуючі прийом/передача - виконання процесу продовжується в фоновому режимі, а програма в потрібний момент може запитати підтвердження завершення приймання повідомлення. Організація неблокуючого обміну повідомленнями наведена на рис.2.8.
Неблокуючий обмін вимагає акуратності при виконанні функцій прийому. Оскільки неблокуючий прийом завершується негайно, для системи неважливо, чи прибуло повідомлення до місця призначення чи ні. Переконатися про це можна за допомогою функції перевірки отримання повідомлення. Звичайно виклик таких функцій розміщується в циклі, який повторюється до тих пір, доки функція перевірки не поверне значення “істина” (перевірка отримання пройшла успішно). Після цього можна викликати функцію прийому повідомлення з буферу повідомлень.

Рис.2.7. Блокуючий обмін повідомленнями

Рис.2.8. Неблокуючий обмін повідомленнями
Колективний обмін . В операціях використовуються не два а більше процесів. Різновидностями обміну є:
широкосмугова передача – передача виконується від одного процесу до всіх;
обмін з бар’єром – форма синхронізації роботи процесів, коли обмін повідомленнями проходить тільки після того, як до певної процедури звернулась певна кількість процесів;
операції приведення – вхідними є дані кількох процесів, а результат – одне значення, яке стає доступним всі процесам, які приймали участь в обміні.
Важливою властивістю системи передачі повідомлень є гарантія збереження порядку прийому повідомлень (при відправленні одним процесом іншому кількох повідомлень вони повинні бути прийняті в тій самій послідовності в якій були відправлені). Більшість реалізацій моделі передачі повідомлень забезпечують цю властивість, але не у всіх режимах обміну.
Паралельна система складається з певної кількості процесорів та модулів пам’яті. В даному випадку це структура з 8 процесорів та спільна пам’ять.
Множення матриці на матрицю або матриці на вектор є базовими мікроопераціями різних задач. Для їх реалізації використовують різні алгоритми та різні структури.
Для вирішення цієї задачі використовується алгоритм, при якому матриця А розбивається на 8 горизонтальних смуг, а матриця В – на 8 вертикальних, в такому разі матриця результату буде складатись з 8 горизонтальних смуг (рис.1.1)

Рис. 1.1 Розбиття матриць
Кожний процес зчитує з пам’яті відповідну підматрицю А та підматрицю В. Після того як процесор помножив під матрицю А на підматрицю В, він обмінюється з іншим процесором підматрицею В. Підматриця А завжди знаходиться у відповідному процесорі, а підматриці В рухаються по всіх процесорах. Отже кожен процес повинен помножити відповідну підматрицю А на всі підматриці В. В результаті всіх множень у пам’яті буде результуюча матриця. Однак обмін підматрицями В між процесорами відбувається не в довільному порядку. Схема обміну відображена у графі (рис. 1.3).

Рис. 1.2 Граф обміну даними між процесорами

Рис. 1.3. Кільцевий граф для обміну підматрицями В0-В7
Розробка функціональної схеми
| Процес0 | Процес7 | Процес2 | Процес4 | Процес6 | Процес1 | Процес5 | Процес3 | | |
| Завантаження | |||||||||
| Z(A0,B0) | | | | | | | | t0 | |
| | Z(A7,B7) | | | | | | | t1 | |
| | | Z(A2,B2) | | | | | | t2 | |
| | | | Z(A4,B4) | | | | | t3 | |
| | | | | Z(A6,B6) | | | | t4 | |
| | | | | | Z(A1,B1) | | | t5 | |
| | | | | | | Z(A5,B5) | | t6 | |
| | | | | | | | Z(A3,B3) | t7 | |
| Множення | |||||||||
| M(A0;B0) | M(A7;B7) | M(A2;B2) | M(A4;B4) | M(A6;B6) | M(A1;B1) | M(A5;B5) | M(A3;B3) | t8 | |
| P(B0)→7 O(B3)←3 | P(B7)→2 O(B0)←0 | P(B2)→4 O(B7)←7 | P(B4)→6 O(B2)←2 | P(B6)→1 O(B4)←4 | P(B1)→5 O(B6)←6 | P(B5)→3 O(B1)←1 | P(B3)→0 O(B5)←5 | t9 | |
| M(A0;B3) | M(A7;B0) | M(A2;B7) | M(A4;B2) | M(A6;B4) | M(A1;B6) | M(A5;B1) | M(A3;B5) | t10 | |
| P(B3)→7 O(B5)←3 | P(B0)→2 O(B3)←0 | P(B7)→4 O(B0)←7 | P(B2)→6 O(B7)←2 | P(B4)→1 O(B2)←4 | P(B6)→5 O(B4)←6 | P(B1)→3 O(B6)←1 | P(B5)→0 O(B1)←5 | t11 | |
| M(A0;B5) | M(A7;B3) | M(A2;B0) | M(A4;B7) | M(A6;B2) | M(A1;B4) | M(A5;B6) | M(A3;B1) | t12 | |
| P(B5)→7 O(B1)←3 | P(B3)→2 O(B5)←0 | P(B0)→4 O(B3)←7 | P(B7)→6 O(B0)←2 | P(B2)→1 O(B7)←4 | P(B4)→5 O(B2)←6 | P(B6)→3 O(B4)←1 | P(B1)→0 O(B6)←5 | T13 | |
| M(A0;B1) | M(A7;B5) | M(A2;B3) | M(A4;B0) | M(A6;B7) | M(A1;B2) | M(A5;B4) | M(A3;B6) | t14 | |
| P(B1)→7 O(B6)←3 | P(B5)→2 O(B1)←0 | P(B3)→4 O(B5)←7 | P(B0)→6 O(B3)←2 | P(B7)→1 O(B0)←4 | P(B2)→5 O(B7)←6 | P(B4)→3 O(B2)←1 | P(B6)→0 O(B4)←5 | t15 | |
| M(A0;B6) | M(A7;B1) | M(A2;B5) | M(A4;B3) | M(A6;B0) | M(A1;B7) | M(A5;B2) | M(A3;B4) | t16 | |
| P(B6)→7 O(B4)←3 | P(B1)→2 O(B6)←0 | P(B5)→4 O(B1)←7 | P(B3)→6 O(B5)←2 | P(B0)→1 O(B3)←4 | P(B7)→5 O(B0)←6 | P(B2)→3 O(B7)←1 | P(B4)→0 O(B2)←5 | t17 | |
| M(A0;B4) | M(A7;B6) | M(A2;B1) | M(A4;B5) | M(A6;B3) | M(A1;B0) | M(A5;B7) | M(A3;B2) | t18 | |
| P(B4)→7 O(B2)←3 | P(B6)→2 O(B4)←0 | P(B1)→4 O(B6)←7 | P(B5)→6 O(B1)←2 | P(B3)→1 O(B5)←4 | P(B0)→5 O(B3)←6 | P(B7)→3 O(B0)←1 | P(B2)→0 O(B7)←5 | t19 | |
| M(A0;B2) | M(A7;B4) | M(A2;B6) | M(A4;B1) | M(A6;B5) | M(A1;B3) | M(A5;B0) | M(A3;B7) | t20 | |
| P(B2)→7 O(B7)←3 | P(B4)→2 O(B2)←0 | P(B6)→4 O(B4)←7 | P(B1)→6 O(B6)←2 | P(B5)→1 O(B1)←4 | P(B3)→5 O(B5)←6 | P(B0)→3 O(B3)←1 | P(B7)→0 O(B0)←5 | t21 | |
| M(A0;B7) | M(A7;B2) | M(A2;B4) | M(A4;B6) | M(A6;B1) | M(A1;B5) | M(A5;B3) | M(A3 ;B0) | t22 | |
| Вивантаження | |||||||||
| W(C0) | | | | | | | | t23 | |
| | | | | | W(C1) | | | t24 | |
| | | W(C2) | | | | | | t25 | |
| | | | | | | | W(C3) | t26 | |
| | | | W(C4) | | | | | t27 | |
| | | | | | | W(C5) | | t28 | |
| | | | | W(C6) | | | | t29 | |
| | W(C7) | | | | | | | t30 | |
Розрахунковий розділ
Дані обраховуються для процесорів з типом завантаження пам’яті «спільна
пам’ять».
Час завантаження це сумарний час завантаження усіма процесорами по одній підматриці А та В.
tU = 10*tS = 3*tP = 2*tZ = 4*tW
Для проведення розрахунків вводяться додаткові параметри:
n1 ─ кількість рядків підматриці А;
n2 ─ кількість стовпців підматриці В;
Завантаження (Tz):
tn – це певний такт, який зображено на функціональній схемі.
t0 = (36*168+168*43)*tz = 13272*tz;
t1 = (38*168+168*48)*tz = 14448*tz;
t2 = (36*168+168*43)*tz = 13272*tz;
t3 = (36*168+168*43)*tz = 13272*tz;
t4 = (36*168+168*43)*tz = 13272*tz;
t5 = (36*168+168*43)*tz = 13272*tz;
t6 = (36*168+168*43)*tz = 13272*tz;
t7 = (36*168+168*43)*tz = 13272*tz;
Загальний час завантаження:
Tz = t0 + t1 + t2 + t3 + t4 + t5 + t6 + t7 = 13272*7 + 14448= 107352*tz = 214704*tw;
Обчислення:
Множення та сумування:
(MAX) – вибираємо підматрицю, в якої найбільша кількість стовпців або рядків.
Tu = (n1(MAX)*N2*n2(MAX))
Ts = (n1(MAX)*n2(MAX)*(N2-1))
t8 = (38*168*48)*tu + (38*48*167)*ts = 306432*tu + 304608*ts = 1225728*tw + 121843.2*tw = 1347571.2*tw;
t10 = (38*168*48)*tu + (38*48*167)*ts = 306432*tu + 304608*ts = 1225728*tw + 121843.2*tw = 1347571.2*tw;
t12 = (38*168*48)*tu + (38*48*167)*ts = 306432*tu + 304608*ts = 1225728*tw + 121843.2*tw = 1347571.2*tw;
t14 = (38*168*48)*tu + (38*48*167)*ts = 306432*tu + 304608*ts = 1225728*tw + 121843.2*tw = 1347571.2*tw;
t16 = (38*168*48)*tu + (38*48*167)*ts = 306432*tu + 304608*ts = 1225728*tw + 121843.2*tw = 1347571.2*tw;
t18 = (38*168*48)*tu + (38*48*167)*ts = 306432*tu + 304608*ts = 1225728*tw + 121843.2*tw = 1347571.2*tw;
t20 = (38*168*48)*tu + (38*48*167)*ts = 306432*tu + 304608*ts = 1225728*tw + 121843.2*tw = 1347571.2*tw;
t22 = (38*168*48)*tu + (38*48*167)*ts = 306432*tu + 304608*ts = 1225728*tw + 121843.2*tw = 1347571.2*tw;
Час множення та сумування загальний (Tu):
Tus = t8 + t10 + t12 + t14 + t16 + t18 + t20 + t22 = 8 * 1347571.2*tw = 10780569.6*tw;
Час операції пересилання (Тр):
Тр = (N2*n2(MAX))
t9 = (168*48)*tp = 8064*tp = 10752*tw;
t11 = (168*48)*tp = 8064*tp = 10752*tw;
t13 = (168*48)*tp = 8064*tp = 10752*tw;
t15 = (168*48)*tp = 8064*tp = 10752*tw;
t17 = (168*48)*tp = 8064*tp = 10752*tw;
t19 = (168*48)*tp = 8064*tp = 10752*tw;
t21 = (168*48)*tp = 8064*tp = 10752*tw;
Загальний час пересилання:
Тр = t9 + t11 + t13 + t15 + t17 + t19 + t21 = 7 * 10752*tw = 75264*tw;
Загальний час обчислення:
Tusp = 10780569.6*tw + 75264*tw = 10855833.6*tw;
Вивантаження (Tw):
Tw = (n1*n2)
Час операції вивантаження ─ це час запису до пам'яті відповідних для кожного процесора результуючих підматриць.
t23 = (36*43)*tw = 1548*tw;
t24 = (36*43)*tw = 1548*tw;
t25 = (36*43)*tw = 1548*tw;
t26 = (36*43)*tw = 1548*tw;
t27 = (36*43)*tw = 1548*tw;
t28 = (36*43)*tw = 1548*tw;
t29 = (36*43)*tw = 1548*tw;
t30 = (38*48)*tw = 1824 * tw;
Загальний час вивантаження (Tw):
Tw = t23 + t24 + t25 + t26 + t27 + t28 + t29 + t30 = 12660*tw;
Загальний час роботи (Т):
T = Tz + Tusp + Tw
T = 214704*tw + 10855833.6*tw + 12660*tw = 11083197.6*tw.
Умовний час виконання послідовного алгоритму
Час завантаження (Tz):
Час завантаження ─ це час вичитки з пам'яті матриць А та B.
Tz = (N1*N2+N2*N3);
Tz = (290*168+168*349)*tz = 107352*tz = 214704*tw;
Час вивантаження (Tw):
Час завантаження ─ це час запису до пам'яті результуючої матриці С з відповідними розмірами (N1хN3).
Tw = (N1*N3);
Tw = (290*349)*tw = 101210*tw;
Час операції пересилання (TP):
Пересилань ніяких не буде, тому час пересилання TPпос = 0.
Час обчислення (Tus):
Tu = (N1*N2*N3)*tu = (290*168*349) *tu = 17003280*tu = 68013120*tw;
Ts = (N1*(N2-1)*N3)*ts = (290*167*349)*ts = 16902070*ts = 6760828*tw;
Tus = 68013120*tw + 6760828*tw = 74773948*tw;
Загальний час роботи (Т):
T = Tz + Tus + Tw = 214704*tw + 74773948*tw + 101210*tw = 75089862*tw.
Ефективність визначається як відношення часу виконання алгоритму на однопроцесорній системі, до часу потрібного для виконання на багатопроцесорній системі, помноженого на кількість процесорів в ній.
E = TПОС / (T * P) = 75089862/(11083197.6*8) ≈ 0,846.
Результат моделювання роботи
Запускаємо виконавчий файл проекту в папці Debug через mpiexec в консолі для моделювання 8 процесів.

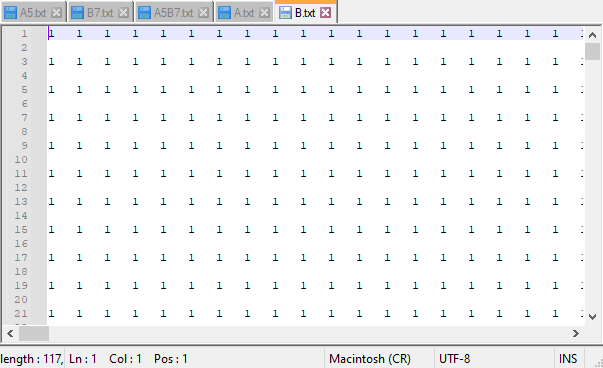
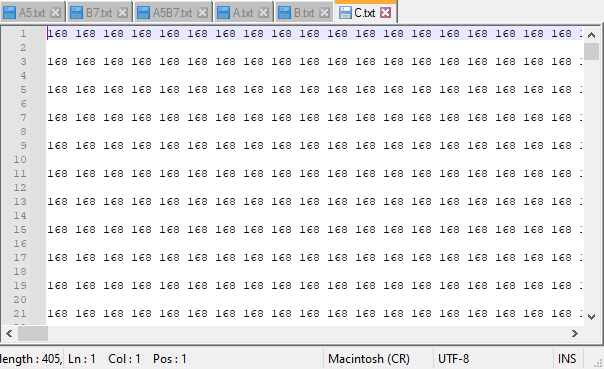
Тепер можна вибрати, щоб програма згенерувала матриці або вписати цифру/число вручну для заповнення всієї матриці. Незалежно від вибору генерація, в консоль буде виводитися послідовний порядок зчитування зі спільної пам’яті.

Якщо вибрати автоматичну генерацію, то потім треба прописати діапазон чисел, в якому будуть створюватися елементи матриць. Тут можна спостерігати процес обміну даними між процесами.
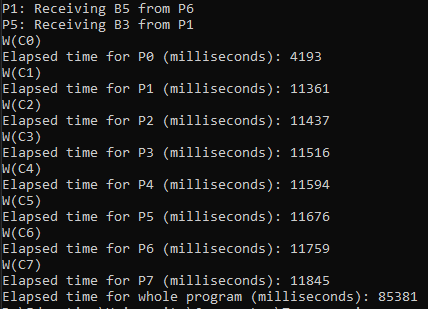
В один момент процеси, по закінченню своєї роботи, починають виводити час виконання всіх дій. В самому кінці виводиться в консоль загальний час.
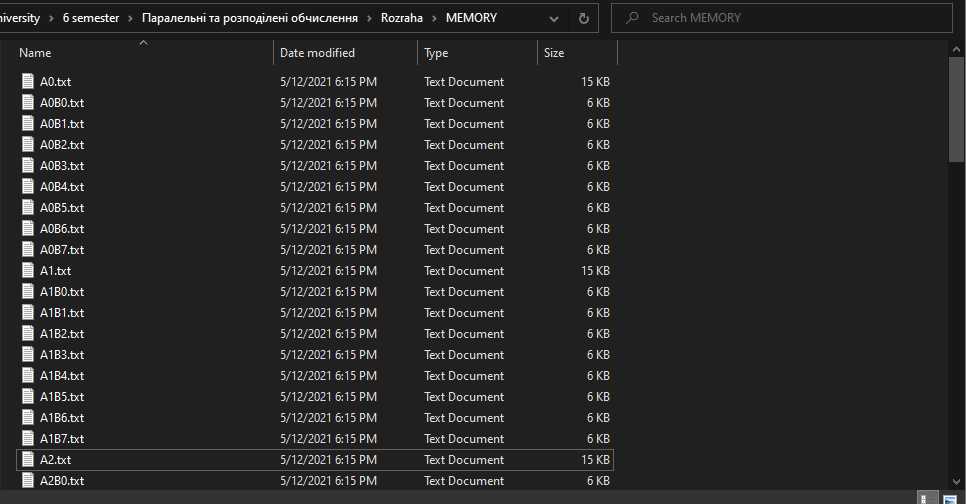
Елементи пам’яті реалізовані завдяки одному текстовому файлу. Відкриваючи його, можна спостерігати результат генерації матриць та їх обчислення.



Нижче буде приведено набір зображень, які ілюструють роботу програми для набору даних з одиницями.




Далі буде представлено зображення роботи програми для послідовного алгоритму множення матриць. Послідовний алгоритм виходить швидше за часом, бо обмін даними в МРІ проекті займає багато часу.


1 2 3 4 5 6 7 8 9