
Ім'я файлу: 40763342.docx
Розширення: docx
Розмір: 95кб.
Дата: 14.02.2020
скачати
Пов'язані файли:
Особливості фізичного виховання дошкільників у США.doc
Розширення: docx
Розмір: 95кб.
Дата: 14.02.2020
скачати
Пов'язані файли:
Особливості фізичного виховання дошкільників у США.doc
Міністерство освіти і науки України
Київський національний університет будівництва і архітектури
Кафедра інформаційних технологій проектування та прикладної математики
ПОЯСНЮВАЛЬНА ЗАПИСКА
до курсової роботи з дисципліни «Теорія алгоритмів»
На тему:«Алгоритм пошуку в рядках. Алгоритм Хорспула»
Виконала студентка групи ІУСТ-21
Сидоренко Є.С
Керівник
Доцент Білощицька С. В.
Національна шкала
Кількість балів
Оцінка ECTS
Члени комісії
(підпис) (прізвище та ініціали)
(підпис) (прізвище та ініціали)
(підпис) (прізвище та ініціали)
м. Київ – 2014 рік
Київський національний унiверситет будiвництва i архiтектури
Кафедра інформаційних технологій проектування та прикладної математики
Спецiальність: Комп’ютерні науки
Курс 2 Група ІУСТ-21 Семестр 3
ЗАВДАННЯ
на курсову роботу студентцi
Cидоренко Єлизаветі
1.Тема роботи «Алгоритми пошуку в рядках. Алгоритм Хорспула.»
2.Термiн здачi студентом закiнченої роботи: 01.12.14
3.Вихiднi данi до роботи: Вхідні дані –строка тексту та частина тексту,яку необхідно знайти , вихідні дані – місце збігу
4.Змiст пояснювальної записки (перелiк питань, які належить розробити:1.Вступна частина; 2.Математичний опис розв’язку задачі; 3.Схема алгоритму; 4.Аналіз алгоритму ; 5.Програмна реалізація алгоритму
5.Перелiк графiчного матерiалу (з точним зазначенням обов’язкових креслень): Схема алгоритму
6. Дата видачі завдання “01” жовтня 2014 р.
Студент __________________ Керiвник ______________________
(пiдпис) (пiдпис)
Зміст
Вступна частина
Поняття алгоритму Хорспула
Вхідні та вихідні дані
Постановка задачі та методи її вирішення
Математичний опис розв’язку задачі
Схема алгоритму
Аналіз алгоритму
Загальна оцінка алгоритму
Програмна реалізація алгоритму
Опис мови
Керівництво користувача
Інтерфейс програми
Робота з програмою
Висновки
Список літератури
Додаток 1 «Код програми»
Вступна частина
Для полегшення роботи та мінімізації витраченого часу створено вже безліч програм,що працюють по різним алгоритмам. Одними з них є алгоритми пошуку,що дозволяють знайти у рядку вказаний підрядок.
Поняття алгоритму Хорспула
Алгоритм Хорспула є одним з алгоритмів пошуку рядка та представляє собою спрощений варіант алгоритму Бойера — Мура.
Вхідні та вихідні дані
В якості вхідних даних до даної задачі виступає рядок тексту та частина тексту,яку необхідно знайти. Текст алфавіту символів A, C, G, T – char s1[]=”F” де F – текст алфавіту. Підрядок – char s2[]=”T”, де T – підрядок тексту.
Вихідними даними є місцезнаходження даного підрядка у заданому рядку,тобто поточна позиція підрядка s2 в тексті s1.
Для розрахунку поточної позиції зразку s2 в тексті s1 використовується програма-функція Horspool(). В Пр-Ф використовуються так зміні:
int i, j, k, needle_len, haystack_len, needle_table[256], char *p,
i – лічильник поточного останнього символу в s1.
j – лічильник поточного символу в s2, k – в s1.
needle_len, haystack_len – довжина s2 та s1 відповідно.
*р – покажчик на символ
needle_table[256] – Для збереження таблиці символів використаємо статичний масив розміром 256, так як таблиця символів ASCII складається з 256-ти символів.
Постановка задачі та методи її вирішення
В даній курсовій роботі необхідно знайти ген в послідовності ДНК з використанням алгоритму Хорспула. Послідовність ДНК являє собою текст алфавіту {A, C, G, T}, а ген або відрізок гену – зразок пошуку.
На вході міститься рядок тексту. Для знаходження підрядка у тексті можна використати безліч методів. В даній курсовій роботі для вирішення поставленої задачі було обрано алгоритм Хорспула.
Математичний опис розв’язку задачі
Спочатку будується таблиця зміщень для шуканого підрядка. Поєднується початок рядка і підрядка .Сама перевірка починається з останнього символу підрядка.
Якщо останній символ підрядка і відповідний йому при накладенні символ рядка не збігаються, то підрядок зміщується відносно рядка на величину, отриману з таблиці зміщень.Прицьому символ береться з рядка,а не з підрядка, відповідний зсув знаходиться в таблиці. Проводиться зміщення і знову починається перевірка з останнього символу.
Якщо ж символи збігаються,то проводиться порівняння передостаннього символу підрядка і т. д. Якщо всі символи підрядка збіглися з накладеними символами рядка, значить, підрядок знайдено, і пошук закінчено. Якщо ж якийсь (не останній) символ підрядка не збігається з відповідним символом рядка, то підрядок зміщується на один символ вправо, і перевірка знову починається з останнього символу. Весь алгоритм виконується до тих пір, поки або не буде знайдено входження шуканого підрядка, або не буде досягнуто кінець рядка.
Побудова самої таблиці дуже проста й робиться для зберігання величини зміщення для кожного символу в підрядку. Величина зміщення визначається таким чином, щоб воно повинно бути максимально можлививим, та при цьому не пропустити входження шуканого підрядка.
Таблиця вміщує список усіх символів в підрядку. У відповідність кожному символу ставиться його порядковий номер, рахуючи з кінця рядка. Якщо символ зустрічається кілька разів, то використовується саме праве входження.
Як приклад,для підрядка «abbad» таблиця має наступний вигляд(див.Таб.1)
| a | b | d |
| 1 | 2 | 5 |
Таблиця-1 Список символів у підрядку.
Схема алгоритму
S1-рядок
S2-підрядок
j-лічильник кіл-ті
неспівпавших елементів
Алгоритм Хорспула
S1
Ні
Так
Таблиця
j=s2
j>0
Ні
Так
Порівнюємо
Не однакові
Порівнюємо s1 та s2 починаючи з елем. S2
однакові
Перехід до попереднього
j=j-1
Вводимо текст s1 та підрядок s2
j>0
Так
Ні
Зсув шаблону згідно таблиці
Результат
Рис.1 Блок-схема алгоритму Хорспула
Початок
s1 ,s2
Алгоритм Хорспула
Результат
Кінець
Р
Таблиця
ис.1.2. Блок-схема головної програми
Tabl[256]
i=1..s2
Таблиця
Tabl[s2-i]=s2-i
Рис.1.3. блок-схема процедури «Таблиця»
Аналіз алгоритмів сортування
Загальна оцінка алгоритму
Алгоритм вигідно відрізняється від інших алгоритмів пошуку своєю відносною швидкодійністю та простотою реалізації .
Недоліками цього алгоритму можна зазначити лише те, він не модифікується на приблизний пошук та одночасний пошук кількох рядків.
Програмна реалізація алгоритму
Опис мови
С — мінімалістична мова програмування. Серед її головних цілей: можливість прямолінійної реалізації компіляції, використовуючи відносно простий компілятор, забезпечити низькорівневий доступ до оперативної пам'яті, формувати лише декілька інструкцій машинної мови для кожного елементу мови, і не вимагати обширної динамічної підтримки. У результаті, код С придатний для більшості системного програмного забезпечення, яке традиційно писалося асемблером.
Незважаючи на її низькорівневі можливості, мова проектувалася для машинно-незалежного програмування. Сумісна зі стандартами та машинно-незалежно написана мовою C програма, може легко компілюватися на великій кількості апаратних платформ та операційних систем з мінімальними змінами. Мова стала доступною для великої кількості платформ, від вбудованих мікроконтролерів до суперкомп'ютерів.
Як і більшість імперативних мов, заснованих на традиції АЛГОЛ, C має можливості для структурного програмування і дозволяє здійснювати рекурсії, у той час, як система статичної типізації даних запобігає виникненню багатьох непередбачуваних операцій. У С увесь виконуваний код міститься у функціях. Параметри функції завжди передаються за значеннями. Передача параметрів за вказівником реалізовується шляхом передачі значення вказівника. Гетерогенні сукупності типів даних (структури) дозволяють пов'язаним типам даних бути об'єднаними і маніпулювати ними, як єдиним цілим.
C також має такі специфічні властивості:
змінні можуть бути прихованими у вкладених блоках
слабка типізація; наприклад, символи можуть використовуватися, як цілі числа
низькорівневий доступ до оперативної пам'яті шляхом перетворення машинних адрес вказівники
вказівники на функції і дані підтримують динамічний поліморфізм
масив індексів як вторинне поняття, визначається у термінах арифметики вказівників
стандартизований препроцесор C для макроозначення, включення файлу з джерельним кодом, умовної трансляції, і т. д.
комплексна функціональність, як то I/O, маніпуляція рядками, і делегування математичних функцій бібліотекам
відносно невелика кількість зарезервованих слів (32 у С89, і 37 у C99)
Лексичні структури, які нагадують B більше за ALGOL, наприклад:
{ ... } на відміну від ALGOL'івського begin ... end
знак рівності для призначення (копіювання), як це робиться у мові Fortran
два знаки рівності використовуються для перевірки рівності (подібно до .EQ. у Fortran'і або одного знаку рівності у BASIC)
&& та || на відміну від ALGOL'івських and та or (цим вона семантично відрізняється від бітових операторів & та |).
велика кількість операторів об'єднання, на кшталт +=, ++, ……
Мова С проектувалась з розрахунком на те, щоб використовуватись у системному програмуванні. Отже, вона не вимагає додаткового часу на виконання перевірок різноманітних умов, які ніколи не відбудуться у правильно написаній програмі, а забезпечує простий, прямий доступ до адреси будь якого об'єкта (наприклад, карти пам'яті, пристрою контролю регістрів), і вираження її джерельного коду може бути переведене у вигляд простої, примітивної машинної операції.
Керівництво користувача
Інтерфейс програми
Інтерфейс програми лаконічний та простий,представлений у вигляді консольного вікна.
Вікно програми містить три кнопки, для швидкого завершення,розгортання програми на весь екран та для її згортання (див.Рис.1).
Рисунок 1 – Вікно програми
Робота з програмою
Робота з програмою дуже зручна,дже дуже легко ввести усі дані й програма підтримує діалог з користувачем.
У першу чергу користувачу надається можливість ввести дані про ген(див.Рис.2):
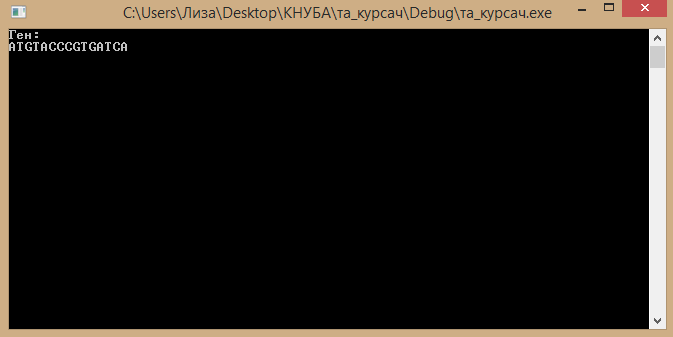
Рисунок 2 – Введення даних про ген
Для підтвердження вводу даних про ген й переходу на наступний крок необхідно натиснути клавішу “ Enter”.
Після цього користувач може ввести частину гену або ген,який необхідно знайти у програмі(див.Рис.3):
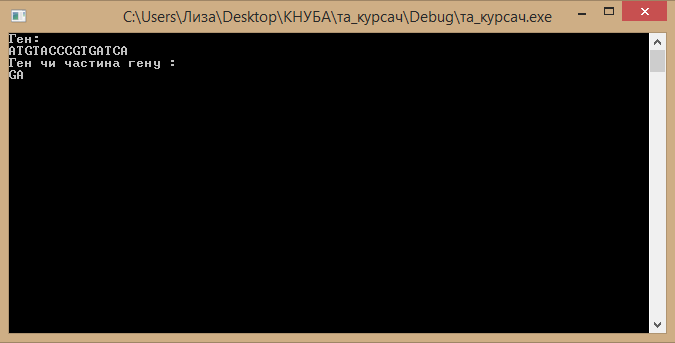
Рисунок 3 – Введення гену або його частини
Підтверджуємо цей крок клавішею “ Enter”, щоб побачити на якій позиції був знайдений потрібний ген або його частина (див.Рис.4):
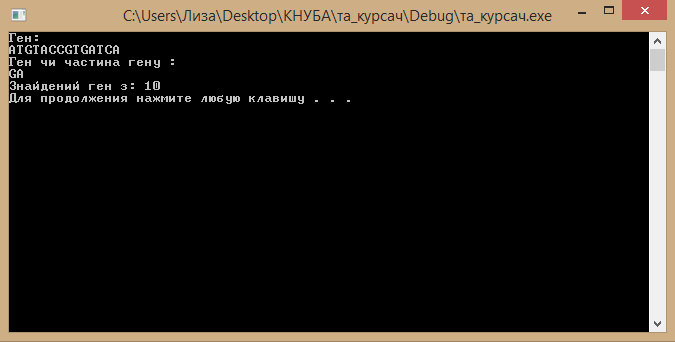
Рисунок 4 – Знайдена позиція шуканого гену чи його частини
Висновки
В даній курсовій роботі було досліджено алгоритм Хорспула, розроблено схему алгоритму та написано програму, що реалізовує його.
Можна сказати,що поставлені задачі були виконані.
Список літератури
А. Конспект лекцій з курсу «Алгоритми і структури даних» Білощицька С.В.
Основы алгоритмизации и программирования. Голицына О.Л., Попов И.И. Москва – 2008.
Абстракция данных и решение задач на Си++. Френк Каррано, Джанет Причард. М. - С. - К. – 2003.
Додаток 1
«Код програми»
#include "stdafx.h"
#include
#include "stdafx.h"
#include
int BoyerMooreHorspool(char *haystack, char *needle)
{
int i,j,k, needle_len = 0,haystack_len = 0;
int needle_table[256];
char *p;
for ( p = needle; *p; *p++)
++needle_len;
for ( p = haystack; *p; *p++)
++haystack_len;
if (needle_len < haystack_len)
{
for (i = 0; i < 256; i++)
needle_table[i] = needle_len;
for (i = 1; i < needle_len; i++)
needle_table[needle[i-1]] = needle_len-i;
i = needle_len;
j = i;
while (j > 0 && i <= haystack_len)
{
j = needle_len;
k = i;
while (j > 0 && haystack[k-1] == needle[j-1])
{
--k;
--j;
}
i+=needle_table[haystack[i-1]];
}
if (k > haystack_len - needle_len)
return 0;
else return k+1;
}
else return 0;
}
int main(int argc, char* argv[])
{setlocale(LC_ALL,"Rus");
char s1[200],s2[100];
printf("Строка:\n");
scanf("%s",s1);
printf("Найти указаную последовательность :\n");
scanf("%s",s2);
printf("Совпадение в: %i\n", BoyerMooreHorspool(s1,s2));
system("pause");
return 0;
}